TensorRT中的int8量化
2022-03-04
神经网络的int8计算是近来神经网络计算优化的方向之一。 本文介绍intel针对cnn的int8量化方案。该方案原理简单直观,并且集成在了tensorrt中,操作实验方便。
前置知识
理解cnn的量化,首先需要理解cnn的kernel计算过程。
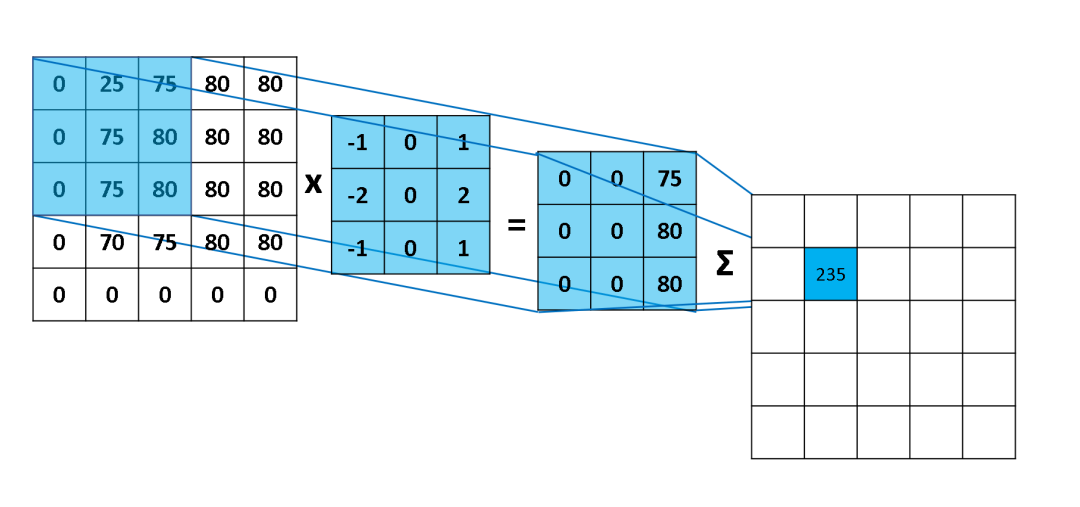
如上图所示,cnn的kernel计算其实就是一个先乘后加的操作。图中展示的整数操作,只是一个示意,正常情况下,这里的计算都是float的。int8计算就是优化这里的kernel操作。
上图中,其实还忽略了一个操作,就是在求和后,还要加上一个bias。在tensorrt提供的量化方案中,bias是没有量化的。
量化概述
为了简化上面的计算,可以使用如下所示的量化过程:
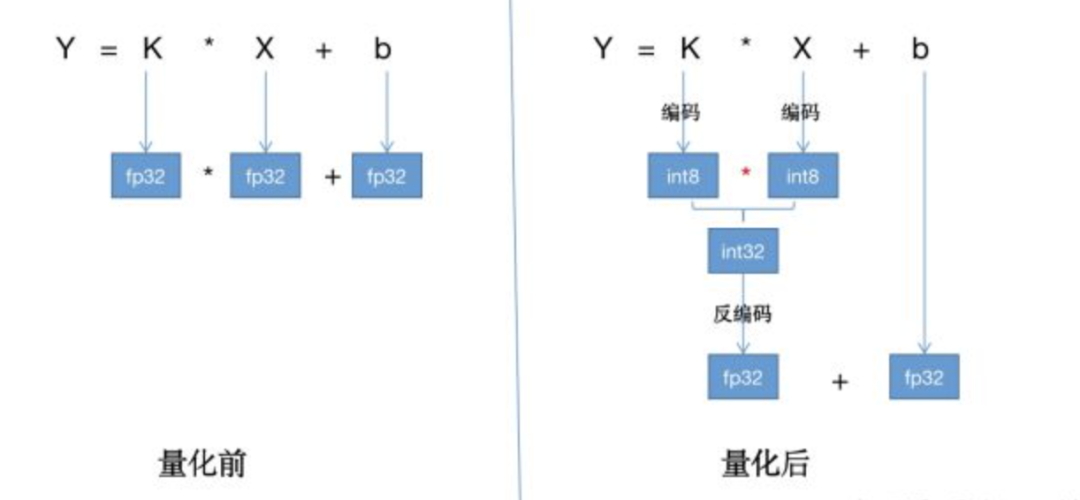
可以看到,量化方案将conv2d-fp32的操作,转化成了如下几个操作的组合:权重编码,即fp32-to-int8-IO、输入编码,即fp32-int8-IO、conv2d-int8操作、输出反编码,即int32-to-fp32-IO。
这样的方案能提高计算速度的依据是,int8的卷积比fp32的卷积性能更高,能够在抵消掉数据转换的开销后,仍然有性能收益。 tensorrt中针对int8的卷积操作进行了特殊优化,非常高效,比如使用cuda针对int8卷积的dp4a api。
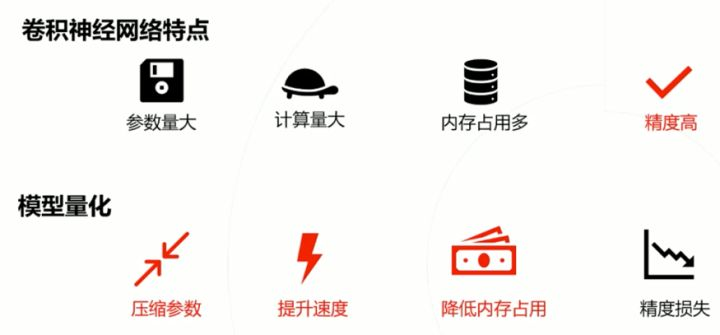
为什么量化操作主要是针对cnn呢?原因是cnn更值得量化。如下图所示:
量化思路
将模型进行量化,目前主流的有三种方法:
-
1、直接将一个浮点参数直接转化成量化数 一般会带来很大的精度损失,但使用上非常简单。
-
2、基于数据校准的方案 它需要转模型的时候提供一些真实的计算数据。这也是本文要介绍的tensorrt使用的方法。
-
3、基于训练finetune的方案 好处是可以带来更大的精度提升,缺点是需要修改训练代码,难度较大。
在实际工程实施中,我们会首先使用第2种方案,如果实施后效果达不到要求,才会尝试第3种方案。我个人的经验是,第2种方案大部分情况下是够用的。
tensorrt量化方案
前面我们知道,所谓量化,核心是将float32的tensor转变为int8的tensor。在卷积操作中,主要是两个float32 tensor,一个是input,一个是kernel。
tensorrt采用的是线性量化方案。实施起来非常简单:

就是直接将float32 tensor表示成一个in8 tensor乘以一个缩放因子。注意,是整个int8 tensor仅使用一个缩放因子!!真正的暴力美学!
那么,现在的问题就是两个:
- 如何确定缩放因子
- 如果计算int8的卷积
int8卷积
确定缩放因子的问题,我们后面再讲,先了解一下int8卷积的整体计算过程。
先看我们需要多少缩放因子:
- input_scale:这是为了将输入tensor转化为int8 tensor
- output_scale:这是为了将卷积计算后的激活值转化为int8 tensor
- weights_scale[K]:这是为了将K个kenel tensor转为int8 tensor,K代表该卷积的channel数。
假设我们已经将weights和input根据缩放因子进行量化,得到I8_weights和I8_input。 那么就可以使用计算int8卷积:
I8_input = input_scale * input
I8_weights = weights_scale * weights
I32_gemm_out = I8_input * I8_weights
F32_gemm_out = (float)I32_gemm_out
此处调用cuda的dp4a api来加速计算。
__device__ int __dp4a(int srcA, int srcB, int c);
注意,要使用这个加速,你的gpu的计算能力要达到sm61,sm61的gpu如下所示: GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030, Titan Xp, Tesla P40, Tesla P4, Discrete GPU on the NVIDIA Drive PX2
当然,比上述更先进的gpu的计算能力也是没有问题的。
此时,F32_gemm_out相比原来float32时,是缩放了 input_scale*weights_scale的,为了得到原来的值,需要rescale一下。同时,为了将最终的输出也用int8表示,我们还需要一个output_scale。二者综合起来,就是下面这样:
For i in 0, ... K-1:
rescaled_F32_gemm_out[ :, i, :, :] = F32_gemm_out[ :, i, :, :] * [ output_scale / (input_scale * weights_scale[ i ] ) ]
i表示的是channel。
按照卷积的计算,还需要加上bias。在tensorrt中,并没有对bias进行量化,所以这里使用的bias就是float32的bias。不过,鉴于我们之前已经对结果进行了output_scale,这里需要对bias进行同样的缩放。
rescaled_F32_gemm_out _with_bias = rescaled_F32_gemm_out + output_scale * bias
下一步,自然是需要进行激活值的计算。这里,我们以relu为例:
F32_result = ReLU(rescaled_F32_gemm_out _with_bias)
计算完激活值,最后转换成int8:
I8_output = Saturate( Round_to_nearest_integer( F32_result ) )
如何确定缩放因子
如下,是float32和int8的表示范围:

为了确定缩放因子,最简单的方法,就是将float32的最大最小值分别对应int8的最大最小值,然后计算出一个缩放因子。
input_scale和weights_scale就可以直接运用上面的方法,因为input和weights中的值比较均匀,所以直接用最大值量化信息不会丢失太多。
关键是激活值的缩放因子,也就是上面代码中的output_scale。因为激活值是大于0的,并且值分布也不均匀。贸然用最大值量化会丢失很多信息。所以tensorrt使用了一个特别的方法。
一句话说,output_scale缩放因子是通过搜索算法计算出来的,目标是使量化前后的信息损失最小。为了衡量信息损失,tensorrt需要用户提供一份校准数据集,同时采用阈值的方法,如下图所示:
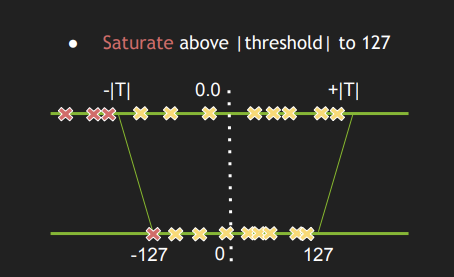
问题是,如何确定这个阈值呢?答案是用校准集来测试。
简单讲,就是用校准数据输入原始模型,获得一组真实的激活值,将收集到的激活值看做一个分布,然后选择一个阈值,确保按阈值量化后的分布和原始分布尽可能接近。使用KL散度衡量两个分布接近程度。

图的出处: https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01