shfl_xor_sync原语
2025-04-22
最近在做一个算子融合的优化时,遇到一个cuda的同步原语,shfl_xor_sync。于是做了一点实验。将实验结果记录下来。
1、shfl_xor_sync作用
根据官方文档,shfl_xor_sync的作用是: exchange a variable between threads within a warp. __shfl_xor_sync() calculates a source line ID by performing a bitwise XOR of the caller’s lane ID with laneMask: the value of var held by the resulting lane ID is returned. If width is less than warpSize then each group of width consecutive threads are able to access elements from earlier groups of threads, however if they attempt to access elements from later groups of threads their own value of var will be returned. This mode implements a butterfly addressing pattern such as is used in tree reduction and broadcast.
简单说,就是交换一个warp中两个线程之间的寄存器变量。 和谁交换是通过xor计算得到的。 有了这个两两交换的逻辑,我们就可以通过迭代进行两两交换,从而实现归约。
其实,看到上面这些文字,对于刚接触这个原语的小伙伴,估计还是有点懵。这时候最好的莫过于一个简单的小例子。 笔者借助cursor,写了一个简单的例子。
2、实验
代码如下:
#include <stdio.h>
// 使用shfl_xor_sync 进行warp内的最大值计算
// nvcc -arch=sm_75 -o shfl_xor_sync_demo shfl_xor_sync_demo.cu
__global__ void warpReduceMax(int* results) {
int laneId = threadIdx.x & 0x1f; // 获取线程在warp中的ID (0-31)
// 初始值为线程ID,这样每个线程有不同的值
int value = threadIdx.x;
// 存储初始值
results[laneId] = value;
// 使用XOR模式进行蝶形归约,计算warp内的最大值
for (int mask = 16; mask > 0; mask /= 2) {
// 从XOR对应的线程获取值
int other = __shfl_xor_sync(0xffffffff, value, mask, 32);
// 更新为当前值和对应线程值的最大值
value = max(value, other);
// 存储每轮归约后的值
// 修正索引计算,使用正确的偏移量
int offset = 0;
if (mask == 16) offset = 1;
else if (mask == 8) offset = 2;
else if (mask == 4) offset = 3;
else if (mask == 2) offset = 4;
else if (mask == 1) offset = 5;
results[laneId + 32 * offset] = value;
}
}
int main() {
// 分配内存存储结果
// 6行数据:初始值、mask=16结果、mask=8结果、mask=4结果、mask=2结果、mask=1结果
int* d_results;
int h_results[32 * 6];
cudaMalloc(&d_results, 32 * 6 * sizeof(int));
// 初始化结果数组为0
cudaMemset(d_results, 0, 32 * 6 * sizeof(int));
// 启动一个block,包含一个完整的warp(32个线程)
warpReduceMax<<<1, 32>>>(d_results);
// 等待GPU完成
cudaDeviceSynchronize();
// 复制结果回主机
cudaMemcpy(h_results, d_results, 32 * 6 * sizeof(int), cudaMemcpyDeviceToHost);
// 检查错误
cudaError_t error = cudaGetLastError();
if (error != cudaSuccess) {
printf("CUDA错误: %s\n", cudaGetErrorString(error));
}
// 定义ANSI颜色代码
const char* RESET = "\033[0m";
const char* RED = "\033[31m";
const char* GREEN = "\033[32m";
const char* YELLOW = "\033[33m";
const char* BLUE = "\033[34m";
const char* MAGENTA = "\033[35m";
const char* CYAN = "\033[36m";
const char* WHITE = "\033[37m";
const char* COLORS[] = {RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE};
const int NUM_COLORS = 7;
// 打印表格标题
printf("| %s线程ID%s | %s初始值%s | %smask=16后%s | %smask=8后%s | %smask=4后%s | %smask=2后%s | %smask=1后(最终值)%s |\n",
CYAN, RESET, YELLOW, RESET, GREEN, RESET, BLUE, RESET, MAGENTA, RESET, RED, RESET, CYAN, RESET);
printf("|--------|--------|-----------|----------|----------|----------|----------------|\n");
// 为每个阶段的分组分配颜色
// 初始值:1组(所有线程一个颜色)
// mask=16:2组(上下各一组)
// mask=8:4组
// mask=4:8组
// mask=2:16组
// mask=1:1组(所有线程一个颜色)
for (int i = 0; i < 32; i++) {
// 获取每个阶段的值
int init_val = h_results[i];
int mask16_val = h_results[i + 32];
int mask8_val = h_results[i + 32*2];
int mask4_val = h_results[i + 32*3];
int mask2_val = h_results[i + 32*4];
int mask1_val = h_results[i + 32*5];
// 为每个值根据分组选择颜色
// 初始值:所有线程一个颜色
const char* init_color = COLORS[0];
// mask=16:分为上下两组(0-15和16-31)
const char* mask16_color = COLORS[i / 16 % NUM_COLORS];
// mask=8:分为4组(0-7, 8-15, 16-23, 24-31)
const char* mask8_color = COLORS[i / 8 % NUM_COLORS];
// mask=4:分为8组(0-3, 4-7, ..., 28-31)
const char* mask4_color = COLORS[i / 4 % NUM_COLORS];
// mask=2:分为16组(0-1, 2-3, ..., 30-31)
const char* mask2_color = COLORS[i / 2 % NUM_COLORS];
// mask=1:所有线程一个颜色(最终都是同一个最大值)
const char* mask1_color = COLORS[1];
printf("| %s%6d%s | %s%6d%s | %s%9d%s | %s%8d%s | %s%8d%s | %s%8d%s | %s%14d%s |\n",
CYAN, i, RESET,
init_color, init_val, RESET,
mask16_color, mask16_val, RESET,
mask8_color, mask8_val, RESET,
mask4_color, mask4_val, RESET,
mask2_color, mask2_val, RESET,
mask1_color, mask1_val, RESET);
}
// 释放内存
cudaFree(d_results);
return 0;
}
以上代码,可以用来计算一个warp内线程的最大值。线程0-31,初始值分别为0-31。计算完成后,每个线程的最终值都是31。
2.1、打印结果
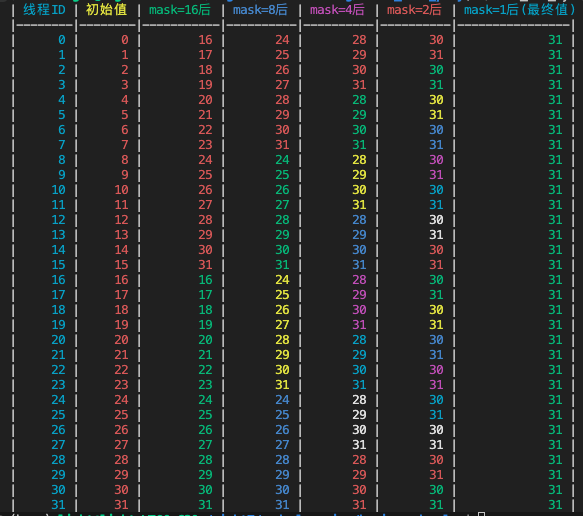
通过结果,可以很清楚看到整个归约的过程。
3、总结
学习这个原语,笔者最大的一点感受就是,善用cursor,实现技术平权。
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01