FlashAttention解读
2025-03-01
解读FlashAttention的原理和极简代码实现。
1、背后直觉
FlashAttention从作者开源到被工业界普遍采纳,大概只用了一周时间,足以说明其价值。
其背后的算法硬件协同优化的思想,很可能会持续成为一种浪潮。最近deepseek开源的各种库,也深刻地体现着这种思想。
作者的突出贡献是敏锐洞察到,Attention 算法是Memory bound的。基于此发现,进一步通过tiling、online softmax等技术,巧妙地通过适当增加计算时间,减少全局内存读写,从而提升整体性能。
2、算法原理
2.1、基本公式
Attention算法的基本公式是:
\[\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d}})V\]传统的cuda实现思路是
要求:矩阵 $Q, K, V ∈ ℝ^{N×d}$ 在HBM中。
1: 按块从HBM加载 $Q, K$,计算 $S = QK^T$,将 $S$ 写入HBM。
2: 从HBM读取 $S$,计算 $P = \text{softmax}(\frac{S}{\sqrt{d}})$,将 $P$ 写入HBM。
3: 按块从HBM加载 $P$ 和 $V$,计算 $O = PV$,将 $O$ 写入HBM。
4: 返回 $O$。
可以看到,涉及到多次HBM的读写,导致延迟很高,成为制约Attention算法性能的瓶颈。
2.2、online softmax
对于向量 $x \in ℝ^B$,可以使用一种稳定的方式来计算softmax值。
\[m(x) = \max(x)\] \[f(x) = [e^{x_1 - m(x)}, e^{x_2 - m(x)}, \cdots, e^{x_B - m(x)}]\] \[l(x) = \sum_{i=1}^B f(x)_i\] \[o(x) = \text{softmax}(x) = \frac{f(x)}{l(x)}\]ok,假设现在有另一个向量$x’ \in ℝ^B$,则其softmax值可通过同样方式计算:
\[m(x') = \max(x')\] \[f(x') = [e^{x_1' - m(x')}, e^{x_2' - m(x')}, \cdots, e^{x_B' - m(x')}]\] \[l(x') = \sum_{i=1}^B f(x')_i\] \[o(x') = \text{softmax}(x') = \frac{f(x')}{l(x')}\]现在,我们将$x$和$x’$拼接成一个向量$y$,即$[x, x’]$。如何能通过上面已有的计算,得到$y$的softmax值?
只需要通过$x, x’$的$m, o, l$,得到$y$的$m, f, l$,进而得到$y$的softmax值。算法如下:
\[m(y) = \max([x, x']) = \max(m(x), m(x'))\] \[f(y) = [e^{m(x) - m(y)} \times o(x) \times l(x), e^{m(x') - m(y)}\times o(x') \times l(x')]\] \[l(y) = e^{m(x) - m(y)}l(x) + e^{m(x') - m(y)}l(x')\] \[o(y) = \text{softmax}(y) = \frac{f(y)}{l(y)}\]按照上面的算法,对于很长的向量,我们可以将其分成不同的子向量,然后通过逐步计算并整合子向量的$m, o, l$,就可以得到最终的softmax值。 这正是Flash Attention采用的思想。
Flash Attention总的思路是将K,V矩阵分块。然后通过循环逐个加载到共享内存。然后计算Q对该分块的注意力结果。
因为是分块,所以得到的注意力结果也是不正确的。不过没关系,我们保存好该分块的$m, l, o$。
等到下一个K、V分块加载到共享内存时,我们利用上一个分块的$m, l, o$,结合针对当前K、V分块计算出新的$m, l, o$。就可以迭代得到新的注意力结果。
整个迭代完成,就可以得到最终正确的注意力结果。
整个算法如下图所示:
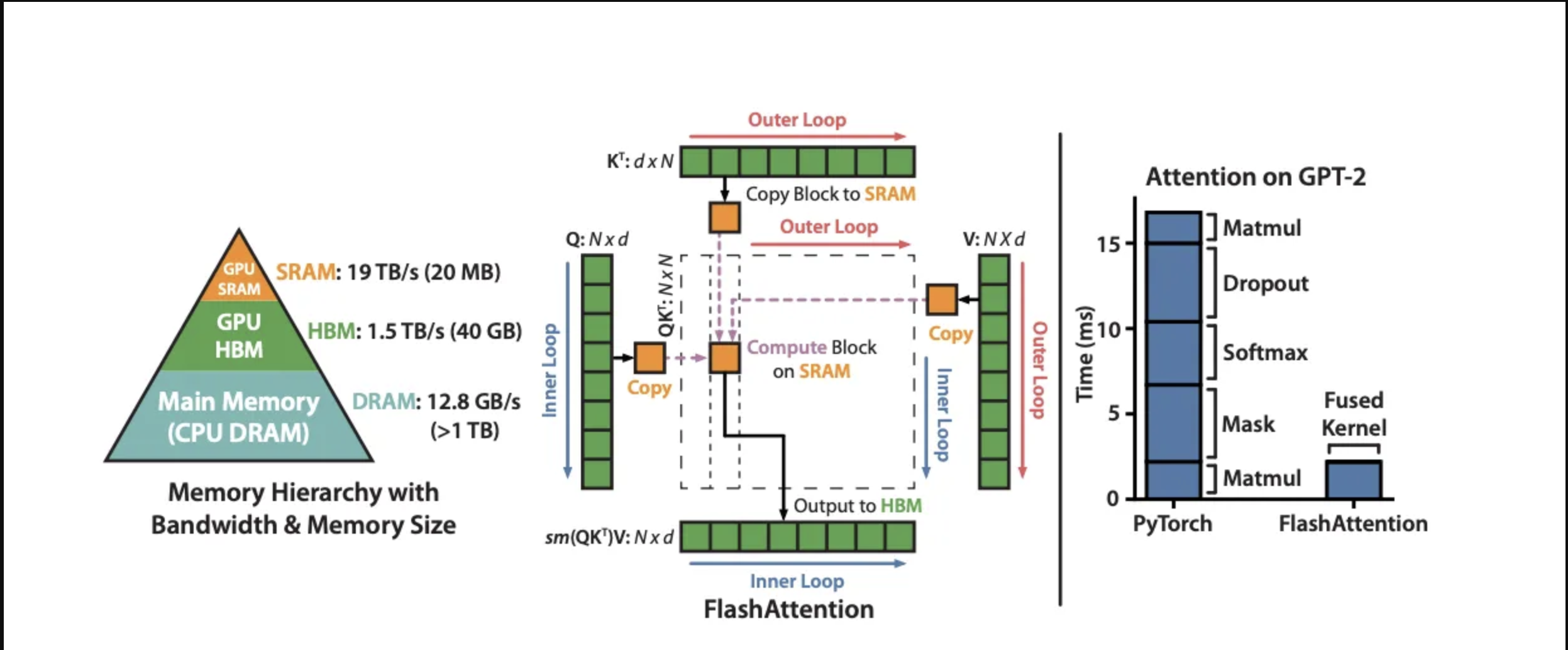
3、伪代码
下面,我们结合伪代码,进行逐行分析。下面的伪代码来自原论文。下面伪代码中开头的向右箭头是用来表示缩进的,方便展示循环层次。
Require: Matrices $Q, K, V \in \mathbb{R}^{N \times d}$ in HBM, on-chip SRAM of size $M$.
1: Set block sizes $B_c = \lceil M/4d \rceil, B_r = \min(\lceil M/4d \rceil, d)$.
$B_c$ 是$K, V$分块的大小,$B_r$ 是$Q$分块的大小。
2: Initialize $O = (0)_{N \times d} \in \mathbb{R}^{N \times d}, \ell = (0)_N \in \mathbb{R}^N, m = (-\infty)_N \in \mathbb{R}^N$ in HBM.
初始化$o, \ell, m$。根据上一节的原理,我们知道,这三个是用来逐步迭代用的。其中的o最终就是我们要的结果。
3: Divide $Q$ into $T_r = \lceil N/B_r \rceil$ blocks $Q_1, …, Q_{T_r}$ of size $B_r \times d$ each, and divide $K, V$ in to $T_c = \lceil N/B_c \rceil$ blocks $K_1, …, K_{T_c}$ and $V_1, …, V_{T_c}$, of size $B_c \times d$ each.
将$Q, K, V$分别进行分块。
4: Divide $O$ into $T_r$ blocks $O_1, …, O_{T_r}$ of size $B_r \times d$ each, divide $\ell$ into $T_r$ blocks $\ell_1, …, \ell_{T_r}$ of size $B_r$ each, divide $m$ into $T_r$ blocks $m_1, …, m_{T_r}$ of size $B_r$ each.
同理,将$o,\ell, m$进行分块,需要留心,这里的分块是与$Q$保持一致的。
5: for 1 ≤ j ≤ T_c do
遍历每一个$K,V$分块。
6: $\rightarrow$Load $K_j, V_j$ from HBM to on-chip SRAM.
将一个$K,V$分块加载到共享内存
7: $\rightarrow\rightarrow$for 1 ≤ i ≤ T_r do
遍历每一个$Q$分块。
8:$\rightarrow\rightarrow$Load $Q_i, O_i, \ell_i, m_i$ from HBM to on-chip SRAM.
将对应的$O, \ell, m$分块加载到共享内存。
9:$\rightarrow\rightarrow$On chip, compute $S_{ij} = Q_i K_j^T \in \mathbb{R}^{B_r \times B_c}$.
在共享内存中计算$Q_i$分块对$K_j$分块的注意力分数矩阵$S_{ij}$。
10:$\rightarrow\rightarrow$ On chip, compute
\[m̃_{ij} = \text{rowmax}(S_{ij}) \in \mathbb{R}^{B_r}\] \[P̃_{ij} = \exp(S_{ij} - m̃_{ij}) \in \mathbb{R}^{(B_r \times B_c)}\] \[\tilde\ell_{ij} = \text{rowsum}(P̃_{ij}) \in \mathbb{R}^{B_r}\]这两步用来计算$Q_i$分块对$K_j, V_j$分块的$m_{ij}, l_{ij}$
11: $\rightarrow\rightarrow$ On chip, compute
\[m_i^{new} = \max(m_i, m̃_{ij}) \in \mathbb{R}^{B_r}\] \[\ell_i^{new} = e^{(m_i-m_i^{new})} \ell_i + e^{(m̃_{ij}-m_i^{new})} \ell_{ij} \in \mathbb{R}^{B_r}\]12:$\rightarrow\rightarrow$ Write
\[O_i \leftarrow \text{diag}(\ell_i^{new})^{-1}(\text{diag}(\ell_i)e^{(m_i-m_i^{new})}O_i + e^{(m̃_{ij}-m_i^{new})}P̃_{ij} V_j)\]to HBM.
这两步就是更新$m, \ell, o$
13: $\rightarrow\rightarrow$ Write
\[\ell_i \leftarrow \ell_i^{new}, m_i \leftarrow m_i^{new}\]to HBM.
14: $\rightarrow$ end for
遍历完$Q$分块后,将$m, \ell, o$写回HBM。
15: end for
遍历完$K,V$分块后,返回$O$。
4、cuda极简实现
这个repo有一个非常简明的cuda实现,是用来学习Flash Attention的很好材料。
下面给出代码,并进行注释。
#include <torch/types.h>
#include <cuda.h>
#include <cuda_runtime.h>
__global__
void forward_kernel(
const float* Q, // 形状: [B, nh, N, d] - 查询矩阵
const float* K, // 形状: [B, nh, N, d] - 键矩阵
const float* V, // 形状: [B, nh, N, d] - 值矩阵
const int N, // 标量 - 序列长度
const int d, // 标量 - 特征维度
const int Tc, // 标量 - K,V的块数量 (向上取整 N/Bc)
const int Tr, // 标量 - Q的块数量 (向上取整 N/Br)
const int Bc, // 标量 - 列块大小
const int Br, // 标量 - 行块大小
const float softmax_scale, // 标量 - softmax缩放因子 (1/sqrt(d))
float* l, // 形状: [B, nh, N] - 每行的累加器值
float* m, // 形状: [B, nh, N] - 每行的最大值
float* O // 形状: [B, nh, N, d] - 输出矩阵
) {
// tx: 当前线程在块内的索引; bx, by: 当前块在网格中的索引,对应批次和注意力头
int tx = threadIdx.x; // 标量 - 线程在块内的索引
int bx = blockIdx.x; // 标量 - 批次索引
int by = blockIdx.y; // 标量 - 注意力头索引
// 计算Q,K,V,O,l,m的偏移量 - 每个批次和头都有不同的偏移
// Offset into Q,K,V,O,l,m - different for each batch and head
int qkv_offset = (bx * gridDim.y * N * d) + (by * N * d); // 标量 - Q,K,V,O的起始偏移
int lm_offset = (bx * gridDim.y * N) + (by * N); // 标量 - l和m的起始偏移
// 在共享内存中为Q,K,V,S分配空间
// Define SRAM for Q,K,V,S
extern __shared__ float sram[]; // 共享内存数组
int tile_size = Bc * d; // 标量 - 每个块(tile)的大小
float* Qi = sram; // 形状: [Br, d] - 当前Q块
float* Kj = &sram[tile_size]; // 形状: [Bc, d] - 当前K块
float* Vj = &sram[tile_size * 2]; // 形状: [Bc, d] - 当前V块
float* S = &sram[tile_size * 3]; // 形状: [Br, Bc] - 注意力分数矩阵
// 外循环:遍历所有的K和V块
for (int j = 0; j < Tc; j++) {
// 将K和V的第j个块加载到共享内存
// Load Kj, Vj to SRAM
for (int x = 0; x < d; x++) {
Kj[(tx * d) + x] = K[qkv_offset + (tile_size * j) + (tx * d) + x]; // 填充Kj[tx, x]
Vj[(tx * d) + x] = V[qkv_offset + (tile_size * j) + (tx * d) + x]; // 填充Vj[tx, x]
}
__syncthreads(); // 同步所有线程,确保Kj和Vj完全加载后再继续
// 内循环:遍历所有Q块,计算与当前K,V块的注意力
for (int i = 0; i < Tr; i++) {
// 将Q的第i个块加载到共享内存,同时加载对应的l和m到寄存器
// Load Qi to SRAM, l and m to registers
for (int x = 0; x < d; x++) {
Qi[(tx * d) + x] = Q[qkv_offset + (tile_size * i) + (tx * d) + x]; // 填充Qi[tx, x]
}
// 读取当前行的前一个最大值和累加器值
float row_m_prev = m[lm_offset + (Br * i) + tx]; // 标量 - 之前计算的最大值
float row_l_prev = l[lm_offset + (Br * i) + tx]; // 标量 - 之前计算的累加器值
// 计算S = Q*K^T并找出每行的最大值row_m
// S = QK^T, row_m = rowmax(S)
float row_m = -INFINITY; // 标量 - 初始化当前块的行最大值
for (int y = 0; y < Bc; y++) {
float sum = 0; // 标量 - 点积结果
// 计算点积
for (int x = 0; x < d; x++) {
sum += Qi[(tx * d) + x] * Kj[(y * d) + x]; // Qi[tx, x] * Kj[y, x]
}
// 应用softmax缩放因子
sum *= softmax_scale;
S[(Bc * tx) + y] = sum; // 填充S[tx, y]
// 更新当前行的最大值
if (sum > row_m)
row_m = sum;
}
// 计算P = exp(S - row_m)并求每行的和row_l
// P = exp(S - row_m), row_l = rowsum(P)
float row_l = 0; // 标量 - 初始化当前块的行和
for (int y = 0; y < Bc; y++) {
// 应用数值稳定性技巧:减去行最大值后再计算exp
S[(Bc * tx) + y] = __expf(S[(Bc * tx) + y] - row_m); // 更新S[tx, y]为exp值
row_l += S[(Bc * tx) + y]; // 累加当前行的和
}
// 计算新的m和l值,使用Flash Attention中的在线softmax更新公式
// Compute new m and l
float row_m_new = max(row_m_prev, row_m); // 标量 - 新的最大值
// 使用在线softmax更新公式更新累加器
float row_l_new = (__expf(row_m_prev - row_m_new) * row_l_prev) + (__expf(row_m - row_m_new) * row_l); // 标量 - 新的累加器值
// 更新输出O,并将新的l和m写回全局内存
// Write O, l, m to HBM
for (int x = 0; x < d; x++) {
float pv = 0; // 标量 - 计算当前块的P*V结果
for (int y = 0; y < Bc; y++) {
pv += S[(Bc * tx) + y] * Vj[(y * d) + x]; // S[tx, y] * Vj[y, x]
}
// 使用Flash Attention中的在线softmax更新公式更新输出
O[qkv_offset + (tile_size * i) + (tx * d) + x] = (1 / row_l_new) \
* ((row_l_prev * __expf(row_m_prev - row_m_new) * O[qkv_offset + (tile_size * i) + (tx * d) + x]) \
+ (__expf(row_m - row_m_new) * pv)); // 更新O[b, h, i*Br+tx, x]
}
// 将新的m和l值写回全局内存
m[lm_offset + (Br * i) + tx] = row_m_new; // 更新m[b, h, i*Br+tx]
l[lm_offset + (Br * i) + tx] = row_l_new; // 更新l[b, h, i*Br+tx]
}
__syncthreads(); // 同步所有线程,确保下一次迭代使用正确的Kj, Vj
}
}
torch::Tensor forward(torch::Tensor Q, torch::Tensor K, torch::Tensor V) {
// Bc和Br是块大小(每个CUDA块处理的序列长度)
// TODO: determine Bc, Br dynamically
const int Bc = 32; const int Br = 32;
// 获取输入张量的维度
const int B = Q.size(0); const int nh = Q.size(1); // 批次大小和注意力头数
const int N = Q.size(2); const int d = Q.size(3); // 序列长度和特征维度
// 计算块的数量(向上取整)
const int Tc = ceil((float) N / Bc); const int Tr = ceil((float) N / Br);
// 计算softmax的缩放因子(1/sqrt(d))
const float softmax_scale = 1.0 / sqrt(d);
// 初始化输出张量O和辅助张量l, m
// Initialize O, l, m to HBM
auto O = torch::zeros_like(Q); // 输出张量初始化为0
auto l = torch::zeros({B, nh, N}); // l张量存储每行的累加器值
auto m = torch::full({B, nh, N}, -INFINITY); // m张量存储每行的最大值,初始化为负无穷
torch::Device device(torch::kCUDA); // 设置设备为CUDA
l = l.to(device); m = m.to(device); // 将l和m移到GPU上
// 计算每个块需要的共享内存大小
// Calculate SRAM size needed per block
const int sram_size = (3 * Bc * d * sizeof(float)) + (Bc * Br * sizeof(float)); // Q,K,V各占Bc*d,S占Bc*Br
int max_sram_size;
// 获取设备支持的最大共享内存大小
cudaDeviceGetAttribute(&max_sram_size, cudaDevAttrMaxSharedMemoryPerBlock, 0);
printf("Max shared memory: %d, requested shared memory: %d \\n", max_sram_size, sram_size);
// 设置CUDA网格和块维度
dim3 grid_dim(B, nh); // 网格维度为批次大小 x 注意力头数
dim3 block_dim(Bc); // 每个块有Bc个线程
// 启动CUDA内核
forward_kernel<<<grid_dim, block_dim, sram_size>>>(
Q.data_ptr<float>(), K.data_ptr<float>(), V.data_ptr<float>(),
N, d, Tc, Tr, Bc, Br, softmax_scale,
l.data_ptr<float>(), m.data_ptr<float>(), O.data_ptr<float>()
);
return O; // 返回计算结果
}
这个实现其实有点问题,Bc和Br不相等时,结果是不对的,这点需要注意。 不过,作为入门学习资料,还是很不错的。
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01