Bank Conflicts简介
2025-03-05
什么是Bank Conflicts?如何解决这个问题?
1、什么是Bank Conflicts?
在cuda里面,可以使用共享内存来加速计算。共享内存在物理上,被分成一个个大小相等的内存模块,每个模块叫做一个Bank。这些Bank之间是可以同时进行读写的。
如果同时有n个读写共享内存的请求,这n个请求访问的共享内存地址恰好在不同的Bank上,那么这n个请求可以同时进行,显然,这能够大大提升访存效率。
如果不巧,n个共享内存地址在一个Bank上,那么这n个读写请求只能顺序进行了,这就是Bank Conflicts。
为了规避Bank Conflicts,就是将多个线程访问的共享内存地址错开,最好是每个Bank上只有一个线程访问,自然就不会出现Bank Conflicts了。
为了达到这个目的,我们需要知道共享内存地址是如何映射到具体的Bank上的。
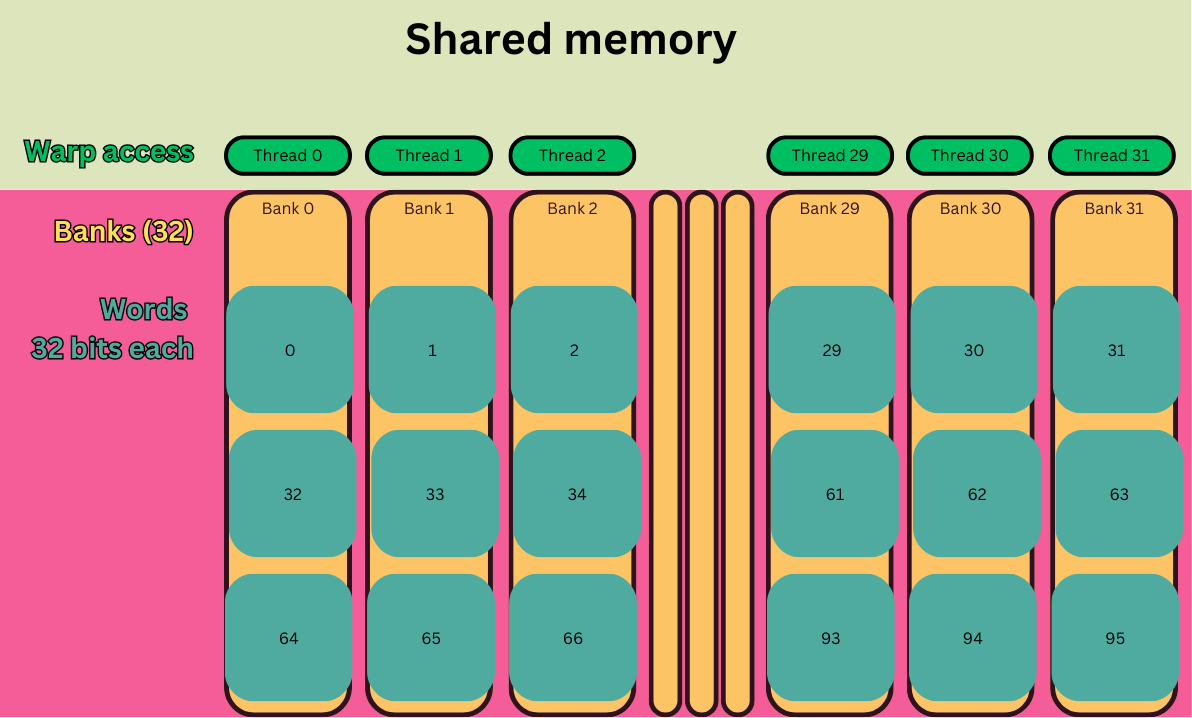
如上图所示,共享内存被划分成了32个Bank。正好和一个warp的线程数量相同。
共享内存地址映射到Bank的方式是:连续的32个地址被映射到连续的不同的32个Bank上。以此类推。
2、上手看看?
下面,我们首先写一个有Bank Conflicts的代码,然后看看如何解决这个问题。
// ncu --metrics l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum,l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum ./bank_conflict_test
__global__ void bank_conflict_test(float *a, float *b, float *c, int N) {
__shared__ float shared_data[256];
int tid = threadIdx.x;
// 加载数据到共享内存
shared_data[tid] = b[tid];
__syncthreads();
// 产生bank conflict的访问模式
// 假设warp大小为32,每个线程访问相隔32个元素的位置
// 这样同一warp中的所有线程都会访问同一个bank
int conflict_idx = (tid % 32) * 32 + (tid / 32);
if (conflict_idx < 256) {
a[tid] = shared_data[conflict_idx] + c[tid];
} else {
a[tid] = b[tid] + c[tid];
}
}
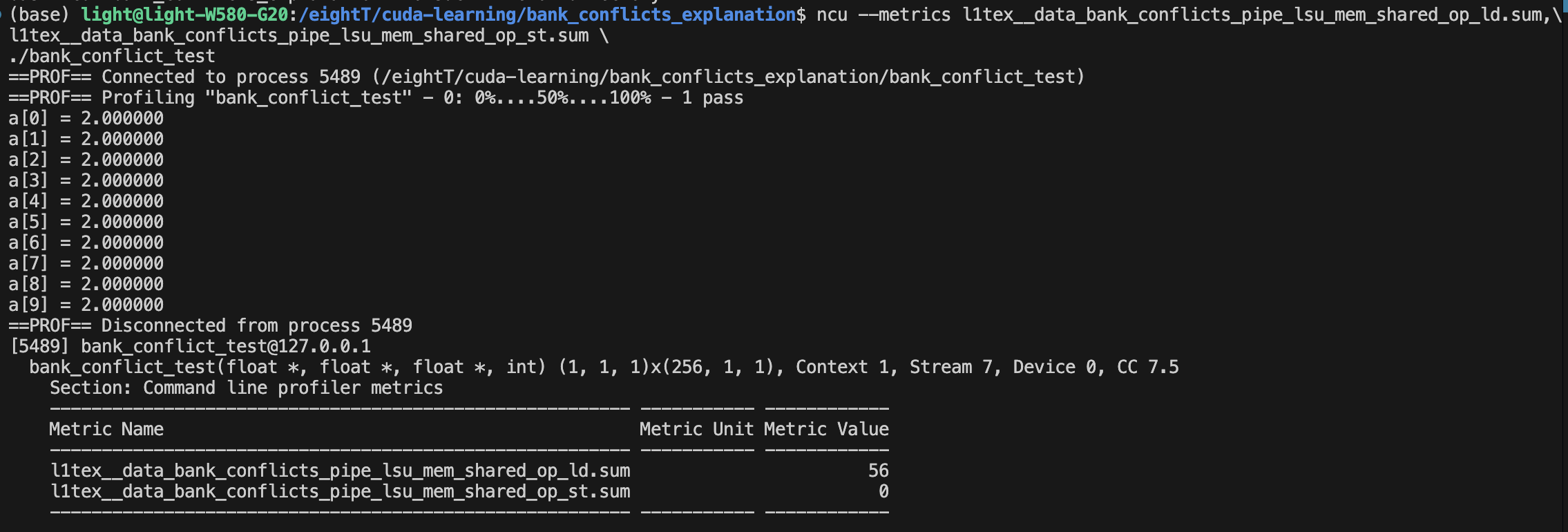
可以看到这种情况下,确实有56次访问共享内存的bank conflict。
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum 后面的ld代表读。
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum 后面的st代表写。
那我们怎么消除呢?如下所示:
// ncu --metrics l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum,l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum ./bank_conflict_test
__global__ void bank_conflict_test(float *a, float *b, float *c, int N) {
__shared__ float shared_data[256];
int tid = threadIdx.x;
// 加载数据到共享内存
shared_data[tid] = b[tid];
__syncthreads();
// 顺序访问,就不会产生bank conflict
int conflict_idx = tid;
if (conflict_idx < 256) {
a[tid] = shared_data[conflict_idx] + c[tid];
} else {
a[tid] = b[tid] + c[tid];
}
}
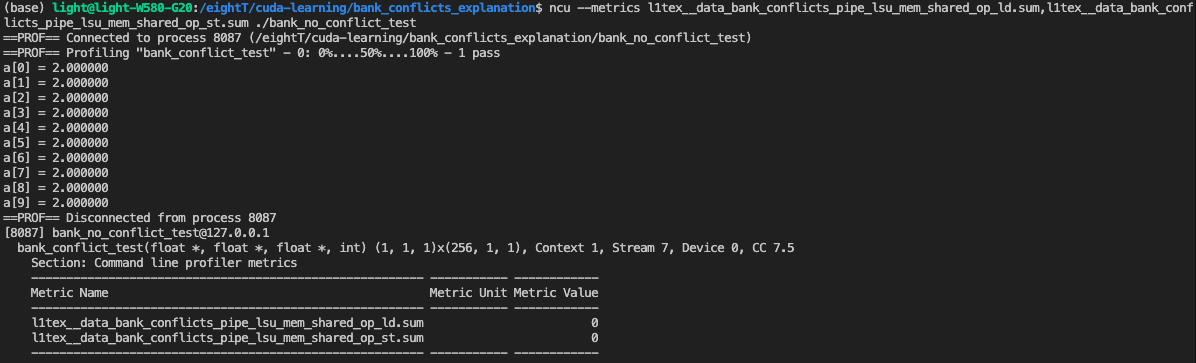
可以看到,bank conflict为 0 。
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01