模型推理速度影响因素分析
2022-02-27
以下是对影响模型推理速度的因素分析,目的是构建总体的分析框架。属于学习笔记,原文在这里,向作者致谢。
1、计算量
计算量越大,推理耗时通常越长。模型的计算量主要有各个算子的计算量相加得到。常说的计算量通常指FLOps(Float Operations)。 pytorch中分析计算量的工具:ptflops。
2、参数量
参数量并不直接影响推理速度,但是会影响内存占用和模型磁盘空间占用,以及程序初始化时间。
3、访存量
访存量是指模型计算时所需访问存储单元的字节大小,反映了模型对存储单元带宽的需求。
访存量一般用 Bytes(或者 KB/MB/GB)来表示,即模型计算到底需要存/取多少 Bytes 的数据。
和计算量一样,模型整体访存量等于模型各个算子的访存量之和。
疑问,除了输入输出需要访存,算子中对参数的访问也算访存的一部分吗?
4、内存占用
内存占用是指模型运行时,所占用的内存/显存大小。需要注意的是,内存占用不等于访存量。 和参数量一样,内存占用不会直接影响推理速度,往往算作访存量的一部分。
5、计算密度与RoofLine模型
计算密度是指一个程序在单位访存量下所需的计算量,单位是 FLOPs/Byte,也称为计算访存比,用于反映一个程序相对于访存来说计算的密集程度。
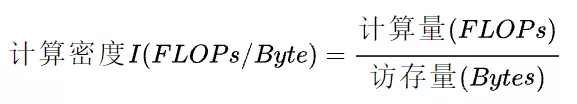
RoofLine 模型是一个用于评估程序在硬件上能达到的性能上界的模型。
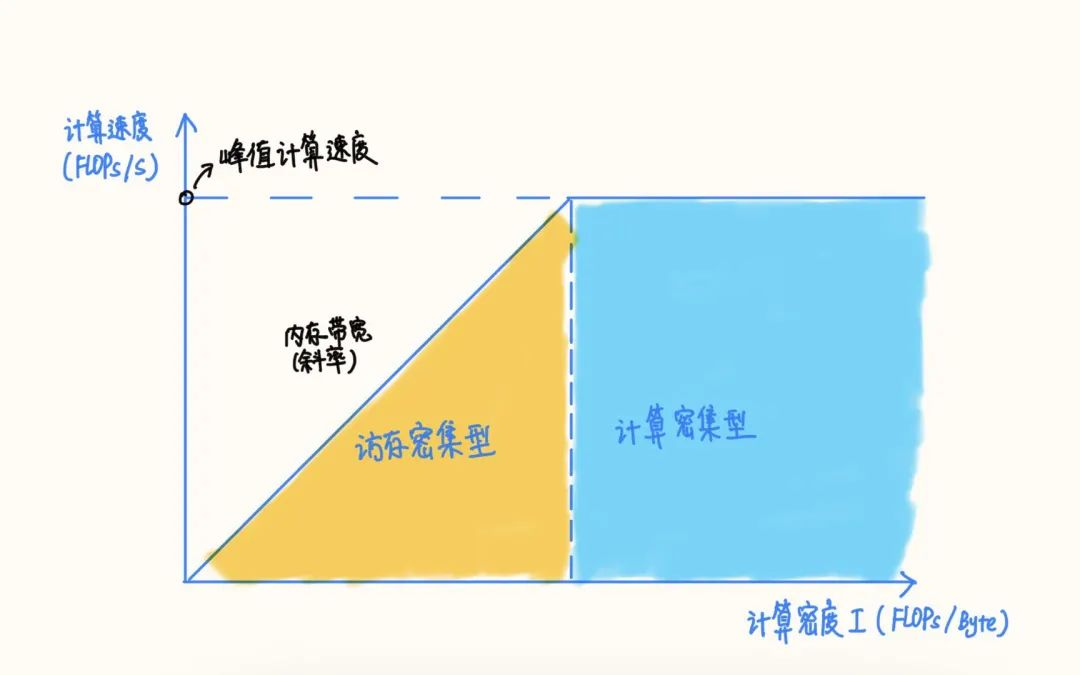

当程序的计算密度I较小时,程序访存多而计算少,性能受内存带宽限制,称为访存密集型程序,即图中橙色区域。在此区域的程序性能上界=计算密度×内存带宽,表现为图中的斜线,其中斜率为内存带宽的大小。计算密度越大,程序所能达到的速度上界越高,但使用的内存带宽始终为最大值。
反之如果计算密度I较大,程序性能受硬件最大计算峰值(下文简称为算力)限制,称为计算密集型程序,即图中蓝色区域。此时性能上界=硬件算力,表现为图中的横线。此时计算速度不受计算密度影响,但计算密度越大,所需内存带宽就越少。
6、计算密集型算子和访存密集型算子
Conv一般来讲,属于计算密集型算子, EltWise Add属于访存密集型算子。
算子的计算密度越大,越有可能提升硬件的计算效率,充分发挥硬件性能。
分析路径时,根据硬件参数,计算峰值性能。
比如E5-2690 v2,基本频率为3.0GHz(这里不考虑Turbo boost动态升频),有10个核,每个核每周期可以做8次双精度浮点运算或16次单精度浮点运算,因此: 单精度峰值浮点性能=3.01016=480 GFLOPs 双精度峰值浮点性能=3.0108=240 GFLOPs
根据最大带宽和峰值性能绘制RoofLine模型曲线。
计算模型的计算密度。在RoofLine模型曲线上绘制出来,模型属于访存密集型还是计算密集型,确定推理优化方向,优化访存或者压榨硬件性能。
7、推理时间的计算方法
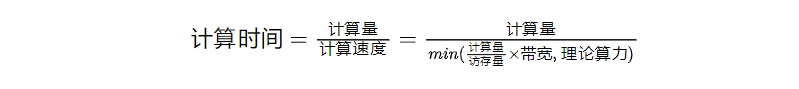
这是一个分段函数,进一步拆分开,可以得到:

对于访存密集型算子,推理时间跟访存量呈线性关系,而对于计算密集型算子,推理时间跟计算量呈线性关系。
结论:计算量并不能单独用来评估模型的推理时间,还必须结合硬件特性(算力&带宽),以及访存量来进行综合评估。并非是计算量越低模型推理越快。在评价模型大小时,也建议加上访存量作为重要的评价指标。
除了峰值算力和内存带宽之外,还有硬件限制、系统环境、软件实现等诸多因素会影响程序的实际性能,使得其非线性特性更加严重。因此 RoofLine 模型仅仅只能提供一个性能上界的评估方式,并不代表能够达到的实际性能。实际性能最准确的测量方式只有真机实测。
测试硬件峰值计算速度的工具: https://github.com/pigirons/cpufp
测试硬件实际最大吞吐的工具: https://www.cs.virginia.edu/stream/
使用教程: https://www.cxyzjd.com/article/Mrhiuser/51353137
除了硬件限制,操作系统,推理框架都会对实际推理时间产生影响。
操作系统对推理时间的影响有内核调度,缺页异常带来的性能损失。
推理框架对模型性能的影响主要体现在:是否充分利用了硬件的流水线资源、是否高效利用了硬件中的缓存、是否采用了时间复杂度更低的算法、是否解决了操作系统带来的性能损失(如上文的调度问题和内存缺页问题)、是否进行了正确高效的图优化等等。
Ref:
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01