pytorch进程间通信
2022-12-31
2023年,训练模型时,使用DDP成为标准的炼丹师技能。DDP本身呢是依赖torch.distributed提供的进程间通信能力。所以,理解torch.distributed提供的进程间通信的原理,对理解DDP的运行机制有很大的帮助。官方的tutorial中,实现了依靠torch.distributed实现DDP功能的demo代码,学习一下,很有裨益。本文将会分成两部分,首先介绍torch.distributed提供的基本功能。然后介绍用torch.distributed实现demo版的DDP。
1、 torch.distributed
这部分,其实就两件事儿,建立进程组和实现进程组之间的通信。
创建进程组
关于建立进程组,说到底,就是建立多个进程,并且将这些进程归并到一起,成为一个group,在group内,每个进程一个id,用于标识自己。 建立多个进程,归根到底,还是一个进程一个进程建立。 那我们想,建立一个进程时,需要怎么做才能达到上面的目的呢。 torch.distributed给我们答案是四个参数:
- MASTER_PORT
- MASTER_ADDR
- WORLD_SIZE
- RANK
MASTER_PORT和MASTER_ADDR的目的是告诉进程组中负责进程通信协调的核心进程的IP地址和端口。当然如果该进程就是核心进程,它会发现这就是自己。 RANK参数是该进程的id,WORLD_SIZE是说明进程组中进程的个数。
看教程的时候,会提到LOCAL_RANK,这个目的是给在一台机器上的进程分配一个单独的id,目的是用来分配资源用,比如gpu。
了解以上这些知识,就可以看一下创建进程组的代码:
"""run.py:"""
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank, size):
""" Distributed function to be implemented later. """
pass
def init_process(rank, size, fn, backend='nccl'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size) #这段代码就是将该进程加入到进程组中的核心代码
fn(rank, size)
if __name__ == "__main__":
size = 2
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
观察代码,可以看到, MASTER_ADDR和MASTER_PORT是通过在代码中设置环境变量传递给torch.distributed的, RANK和WORLD_SIZE是通过参数传递的,其实也可以通过设置环境变量的方式传递。
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
os.environ["RANK"] = str(rank)
os.environ["WORLD_SIZE"] = str(size)
# 一般分布式GPU训练使用nccl后端,分布式CPU训练使用gloo后端
dist.init_process_group(backend="nccl", init_method="env://")
fn(rank, size)
init_method的值env://表示,需要的四组参数信息都在环境变量里取。
init_process_group中还有一个参数,backend,它是pytorch进程组使用的底层通信机制,gpu时,常用nccl,这是英伟达推出的gpu间通信库,cpu时常用gloo。另外,还支持mpi后端,一般用的较少,可以暂时忽略。
这里的run就是在初始化好进程组之后执行的函数,这里之所以传入rank 和size,是想在执行过程中根据不同的rank,来给不同的进程赋予不同的行为,比如,日志只在rank==0的进程中打印等。实际上,如果已经初始化了进程组,也可以通过如下两个函数获取相应的值,避免在函数中传递这两个参数。
def get_world_size() -> int:
"""Return the number of processes in the current process group."""
if not dist.is_available() or not dist.is_initialized():
return 1
return dist.get_world_size()
def get_rank() -> int:
"""Return the rank of the current process in the current process group."""
if not dist.is_available() or not dist.is_initialized():
return 0
return dist.get_rank()
这段代码是官方给的demo,看过之后,不免有些疑惑。这个代码似乎只适用于单机多卡的情况。 对于多机多卡的情况,在不同的机器上执行这个代码,MASTER_PORT 和MASTER_ADDR不用变,WORLD_SIZE需要调整为4,因为我们的代码每台机器上都启动两个进程, RANK这个时候就会发生冲突,不同的机器上的进程有相同的编号。解决方法就是在执行初始化函数时,传递一个NODE_RANK和NPROC_PER_NODE的参数,通过NODE_RANK和NPROC_PER_NODE计算出各个进程的RANK值,就可以保证不冲突了。 代码示例如下。
for r in range(NPROC_PER_NODE):
RANK = NODE_RANK*NPROC_PER_NODE + r
实际上,torch已经将上面这些计算过程帮我们封装好了。代码如下所示:
python -m torch.distributed.launch \
--master_port 12355 \ #主节点的端口
--nproc_per_node=8 \ #每个节点启动的进程数
--nnodes=nnodes \ #节点总数
--node_rank=1 \ # 当前节点的rank
--master_addr=master_addr \ #主节点的ip地址
--use_env \ #在环境变量中设置LOCAL_RANK
train.py
使用这段代码启动train.py时,原先的
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
os.environ["RANK"] = str(rank)
os.environ["WORLD_SIZE"] = str(size)
# 一般分布式GPU训练使用nccl后端,分布式CPU训练使用gloo后端
dist.init_process_group(backend="nccl", init_method="env://")
fn(rank, size)
可以简单改成:
dist.init_process_group(backend="nccl", init_method="env://")
fn()
需要的四个环境变量参数,torch.distributed.launch都会帮我们设置好。fn中需要rank和size的地方,使用上面的两个便利函数即可。
进程组间的通信
常见的进程组间的通信模式有如下几种:
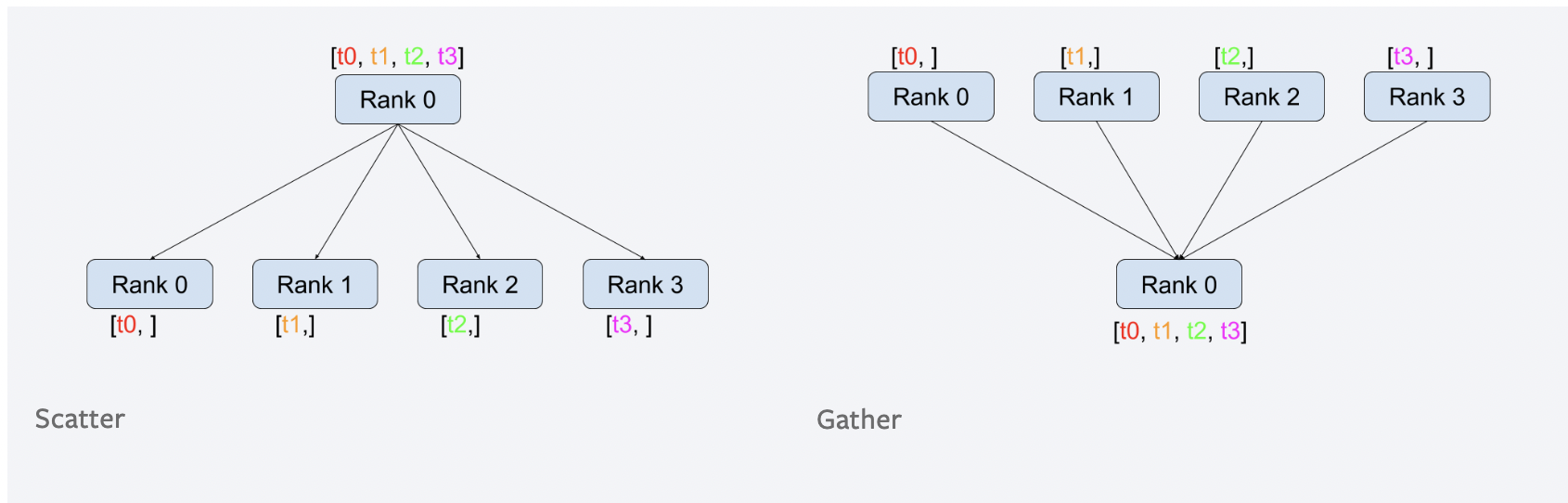
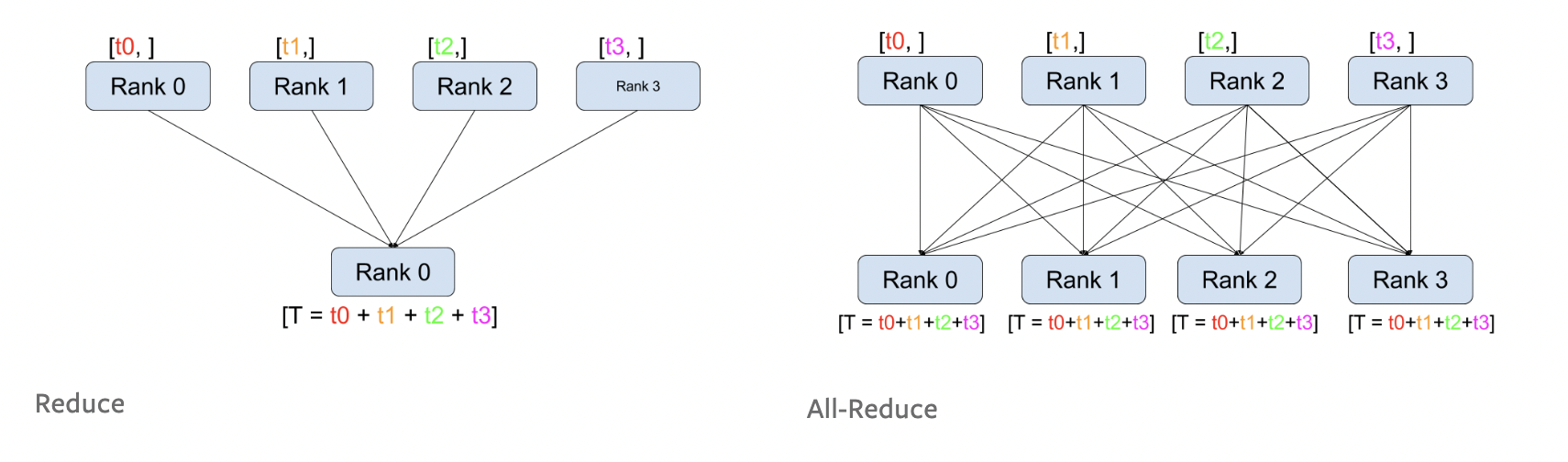
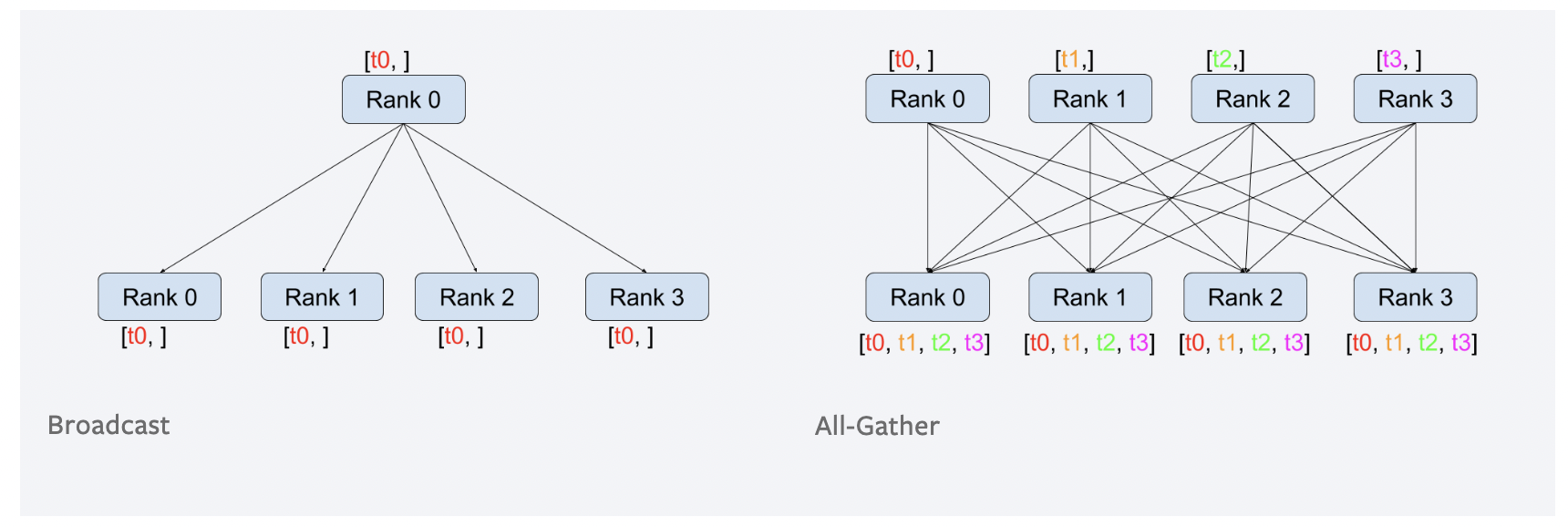
github图床有时无法正确显示图片,如果上面的图无法显示,可以点开下面的链接看官方原图。
原始地址:https://pytorch.org/tutorials/_images/scatter.png
原始地址:https://pytorch.org/tutorials/_images/reduce.png
原始地址:https://pytorch.org/tutorials/_images/broadcast.png
这个图还是非常形象的,认真看一遍,基本能把握通信的常见类型。 试想一下,在我们的分布式训练中,我们需要什么通信类型?
最容易想到的,就是梯度,在每个进程中,将其他进程的梯度汇总过来,求平均,更新。这其实就是all_reduce。
这里,我们给出一个gather_object的示例代码。首先看一下gather_object的api文档:
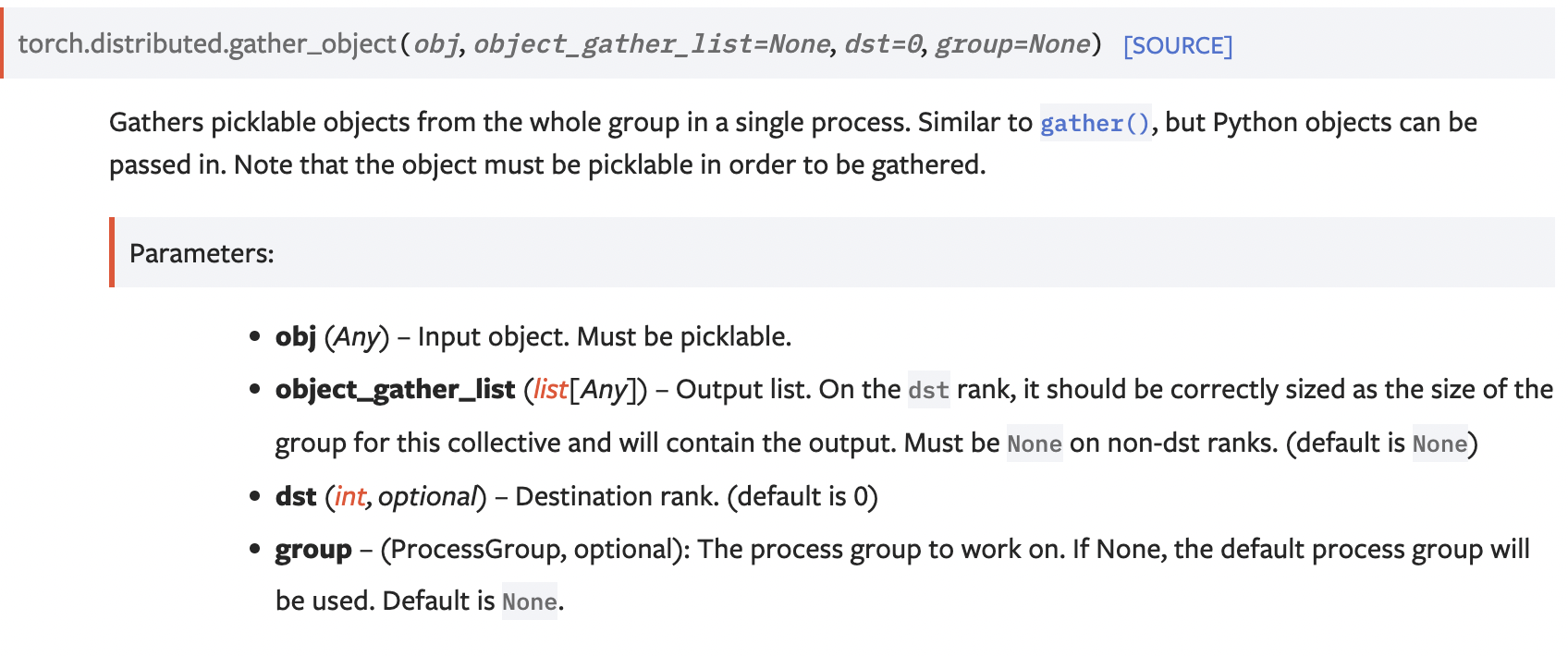
如下是使用gather_ojbect的一个例子:
@functools.lru_cache()
def _get_global_gloo_group():
if dist.get_backend() == "nccl":
return dist.new_group(backend="gloo")
else:
return dist.group.WORLD
def gather_object(data, dst=0, group=None):
world_size = dist.get_world_size()
if world_size == 1:
return [data]
if group is None:
group = _get_global_gloo_group() # use CPU group by default, to reduce GPU RAM usage.
world_size = dist.get_world_size(group=group)
rank = dist.get_rank(group=group)
if rank == dst:
#要把数据收集到dst进程中
#所以output需要是size为world_size
#的list
output = [None for _ in range(world_size)]
dist.gather_object(data, output, dst=dst, group=group)
return output
else:
# 对于非目标进程output需要设置为None
dist.gather_object(data, None, dst=dst, group=group)
return []
以上代码中需要单独说明一下的是_get_global_gloo_group这个方法。 简而言之,这个方法就是,当发现进程组是nccl后端时,复制一个新的进程组,它的后端是gloo,这样,gather_object可以减少对gpu的显存占用。我没有实际验证过,参考资料中有作者验证了。
2、使用distributed实现DDP功能
这部分也分成两部分,一是实现分布式的Dataset,让不同的进程在同一训练step中,使用不同的数据。二是实现梯度的平均和更新。
分布式的数据
为了让不同的进程使用不同的数据,我们可以根据进程组中进程的数量,将data分成不同的份数,然后根据RANK值,给每个进程确定其中的一份。 分成不同份数的代码:
""" Dataset partitioning helper """
class Partition(object):
def __init__(self, data, index):
self.data = data
self.index = index
def __len__(self):
return len(self.index)
def __getitem__(self, index):
data_idx = self.index[index]
return self.data[data_idx]
class DataPartitioner(object):
def __init__(self, data, sizes=[0.3333, 0.3333, 0.3333], seed=1234):
#参数sizes中的值一般设为 1/world_size,即表示给每个进程分配相等的数据
self.data = data
self.partitions = []
rng = Random()
rng.seed(seed)
data_len = len(data)
indexes = [x for x in range(0, data_len)]
rng.shuffle(indexes)
for frac in sizes:
part_len = int(frac * data_len)
self.partitions.append(indexes[0:part_len])
indexes = indexes[part_len:]
def use(self, partition):
return Partition(self.data, self.partitions[partition])
根据进程的RANK值使用不同的数据的示例代码如下:
""" Partitioning MNIST """
def partition_dataset():
dataset = datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
size = dist.get_world_size()
bsz = 128 / float(size)
partition_sizes = [1.0 / size for _ in range(size)]
partition = DataPartitioner(dataset, partition_sizes)
#核心就是下面这句,确保了不同的进程加载的数据的不同部分
partition = partition.use(dist.get_rank())
train_set = torch.utils.data.DataLoader(partition,
batch_size=bsz,
shuffle=True)
return train_set, bsz
有了数据,下面就可以进行训练了,只要在梯度那里,做一下平均即可。
""" Distributed Synchronous SGD Example """
def run(rank, size):
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = Net()
optimizer = optim.SGD(model.parameters(),
lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
for epoch in range(10):
epoch_loss = 0.0
for data, target in train_set:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
epoch_loss += loss.item()
loss.backward()
average_gradients(model)
optimizer.step()
print('Rank ', dist.get_rank(), ', epoch ',
epoch, ': ', epoch_loss / num_batches)
average_gradients 的具体代码,就是进程间通信,做梯度平均的:
""" Gradient averaging. """
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= size
需要注意的时,这个方法一定要在loss.backward()之后调用,确定param.grad.data已经是最新的数据。
以上只是官方给出的一个demo,在实际生产中,将数据分成不同的部分,我们可以使用给dataloader传递一个distributedsampler来实现。 示例代码如下:
train_sampler = DistributedSampler(train_dataset) if is_distributed else None # [Step 2]
# DistributedSampler will do shuffle, so we set `shuffle=False`
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler,
shuffle=(train_sampler is None))
梯度平均部分,我们可以直接将模型包进DistributedDataParallel来实现,示例代码如下:
if is_distributed:
model = DistributedDataParallel(model, device_ids=[local_rank]) # [Step 3]
这里,同时指定device_id,需要使用到参数local_rank。
3、references
WRITING DISTRIBUTED APPLICATIONS WITH PYTORCH
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01