keras中Layer源码解读(上)
2022-02-21
keras对神经网络的抽象,都在Layer中,Model也是一种特殊的Layer。今天开始,我们就来看看Layer的源代码。
版本
keras 2.3.1
Layer类所在目录:keras.engine.base_layer.py
阅读策略
一行一行读,力争搞清楚每一行的含义
大略观察
一共有1474行代码,如果每天读上300行,几天就可以全部读完了。
第1-2行
”"”Contains the base Layer class, from which all layers inherit. “””
包含基本的Layer class。所有的layer都要继承它。
Note:1-2行,表示左右均包含,下同。
第3-20行
一些import,扫了一眼,主要有以下值得注意的地方:
K
这个代表后端,现在只支持tensorflow了。其所在目录是:
keras.backend
从该包的__init__.py文件中,可以看到K支持的操作。
 大概有150多个支持的操作。以后写代码时,想要实现某个操作,又不知道用哪个函数时,应该先到这里来找找看,应该不会失望。
大概有150多个支持的操作。以后写代码时,想要实现某个操作,又不知道用哪个函数时,应该先到这里来找找看,应该不会失望。
initializers
各种初始化器
其他的就是一些小方法了,比如
count_params
has_arg
to_list
这些就留到下面使用时再看,应该更容易理解
25-35
总体来说,这是一个disable_tracking注解。我理解,当不需要追踪某个函数的执行状况时,可以用这个注解。代码也比较好理解:
_DISABLE_TRACKING = threading.local()
_DISABLE_TRACKING.value = False
def disable_tracking(func):
def wrapped_fn(*args, **kwargs):
global _DISABLE_TRACKING
prev_value = _DISABLE_TRACKING.value
_DISABLE_TRACKING.value = True
out = func(*args, **kwargs)
_DISABLE_TRACKING.value = prev_value
return out
return wrapped_fn
36-107
主要是Layer类的注释。
input/output
为了理解这两个属性,我跳转到了input所在代码行:
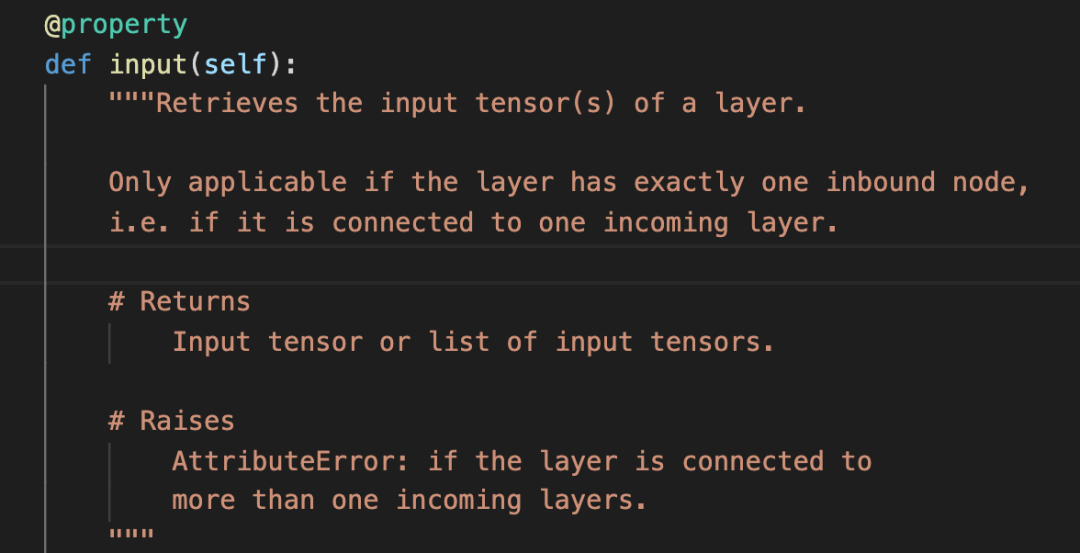
原来主要是返回该层的输入tensor。但是有一个前提,就是这个Layer只有一个输入layer,如果有多个输入layer,也就是这个layer被重用了,就会报如下的错:
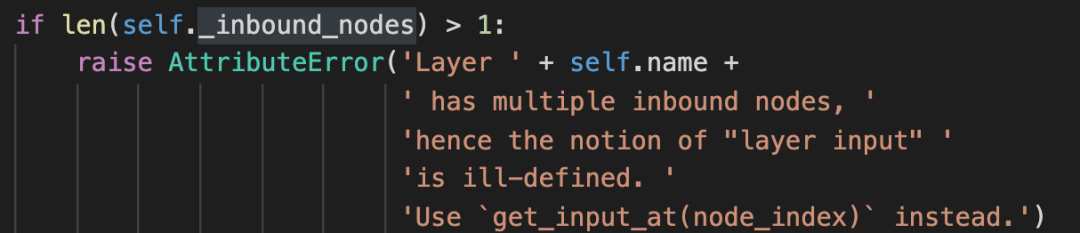
当然,如果压根就没有输入Layer,也会报错:
 贴出这两张图,主要是让自己能记住这些报错信息,以后遇到时,能快速判断出哪里出了问题。
贴出这两张图,主要是让自己能记住这些报错信息,以后遇到时,能快速判断出哪里出了问题。
尽快把自己训练成强大的人肉debug机器!
一切正常的话,就会调用这个方法:
self._get_node_attribute_at_index(0, 'input_tensors','input')
为了理解这个方法,我又跳转到了这个方法所在的代码:
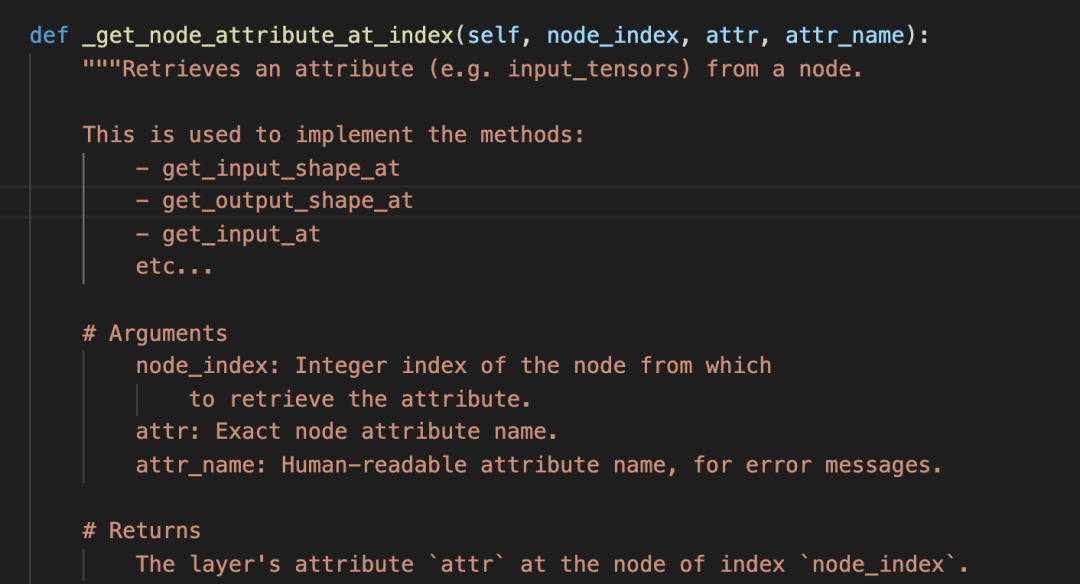
看说明,这个方法很强了,许多方法都是用它实现的。
简单讲,它是用来获得一个node的各个属性的。通过对代码实现的考察,发现这里的node,指的是layer的输入layers。对于所有该layer的输入layer,都会存到 _inbound_nodes这个数组中。

这里也指明了,是通过self._add_inbound_node()方法添加的。
这个方法的名字我觉得需要格外记一下,因为有过太多次,碰到layer属性相关的报错了。
这个方法有三个参数:
第一个参数:node_index,指明从哪个node中提取属性。这个node_index就是数组_inbound_nodes的索引。
第二个参数:属性的准确名称,这是给程序用的
第三个参数:给人读的属性名称,主要用来展示错误信息
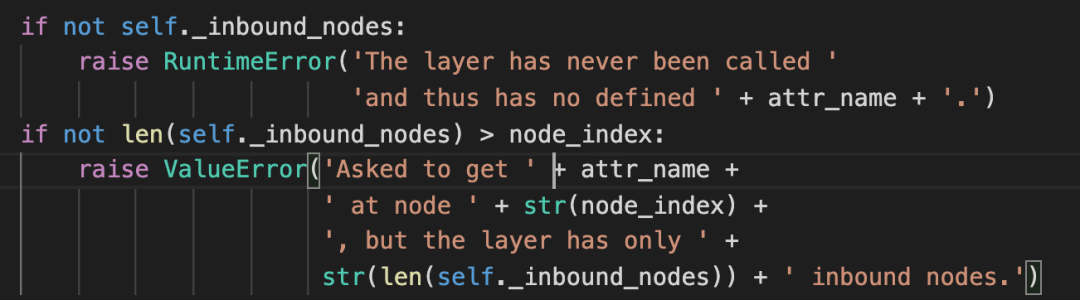
这里首先处理了两种错误,分别是该layer没有_inbound_nodes数组,和数组越界。
如果没有错误,就会取属性了。
 getattr方法,很显然就是取出属性。
getattr方法,很显然就是取出属性。
unpack_singleton方法,我查了下源码:
def unpack_singleton(x):
"""Gets the first element if the iterable has only one value.
Otherwise return the iterable.
# Argument
x: A list or tuple.
# Returns
The same iterable or the first element.
"""
if len(x) == 1:
return x[0]
return x
一目了然。
input还有一点,就是如果layer被重用了,那它就有多个input node。这是获取input会报错。正确的做法就是 使用
layer.get_input_at(node_index)
output和input类似
input_mask和output_mask与output和input类似。input_shape也是类似。
input_spec
看了说明,这个参数是对该layer的输入tensor进行限制的。
主要是维度和数据类型。
具体的是通过InputSpec来说明的。
于是,我又转到了InputSpec的源码。
class InputSpec(object):
"""Specifies the ndim, dtype and shape of every input to a layer.
Every layer should expose (if appropriate) an `input_spec` attribute:
a list of instances of InputSpec (one per input tensor).
A None entry in a shape is compatible with any dimension,
a None shape is compatible with any shape.
# Arguments
dtype: Expected datatype of the input.
shape: Shape tuple, expected shape of the input
(may include None for unchecked axes).
ndim: Integer, expected rank of the input.
max_ndim: Integer, maximum rank of the input.
min_ndim: Integer, minimum rank of the input.
axes: Dictionary mapping integer axes to
a specific dimension value.
"""
def __init__(self, dtype=None,
shape=None,
ndim=None,
max_ndim=None,
min_ndim=None,
axes=None):
self.dtype = dtype
self.shape = shape
if shape is not None:
self.ndim = len(shape)
else:
self.ndim = ndim
self.max_ndim = max_ndim
self.min_ndim = min_ndim
self.axes = axes or {}
第一句话已经说的很清楚了。需要注意的是,注释中说每个Layer都应该暴露一个input_spec属性。
说明这个属性是给需要调用该Layer的人看的,告诉他,该Layer需要什么样的输入。
这种设计方式值得学习,比如我们自己的接口设计时,是不是也可以设计这么一个属性,帮助使用者了解,我们需要 什么样的输入。
还有一点,None在这里表示的意思是unchecked,就是需要在运行时确定,用户可以自己确定。
其他需要关注的属性
name,没啥说的,就是层的名字,建议起个自己好记的名字
stateful 是否有不是weight的状态,rnn就是典型的应用。
supports_masking 是否支持mask,keras中支持Layer不多,不是逼不得已,尽量不用
trainable weight是否需要做梯度更新
uses_learning_phase 是否使用了K.in_training_phase()和K.in_test_phase()具体看源码咋用的
trainable_weights,non_trainable_weights,weights,就是名字的含义
dtype 数据类型
至此,将Layer的属性已经基本搞清楚了。其他行的代码是对方法的简单说明,等进一步读源码时再具体理解。
此时,心中有个疑问,Node和Layer究竟是什么关系?下篇文章,就先解决这个问题。再继续。
继续从36-107行代码读起,先解决上次留下的问题,Node和Layer的区别与联系。
36-107
Layer是什么已经基本清楚了,关键是Node。找到Node的源码所在地。如下图所示:
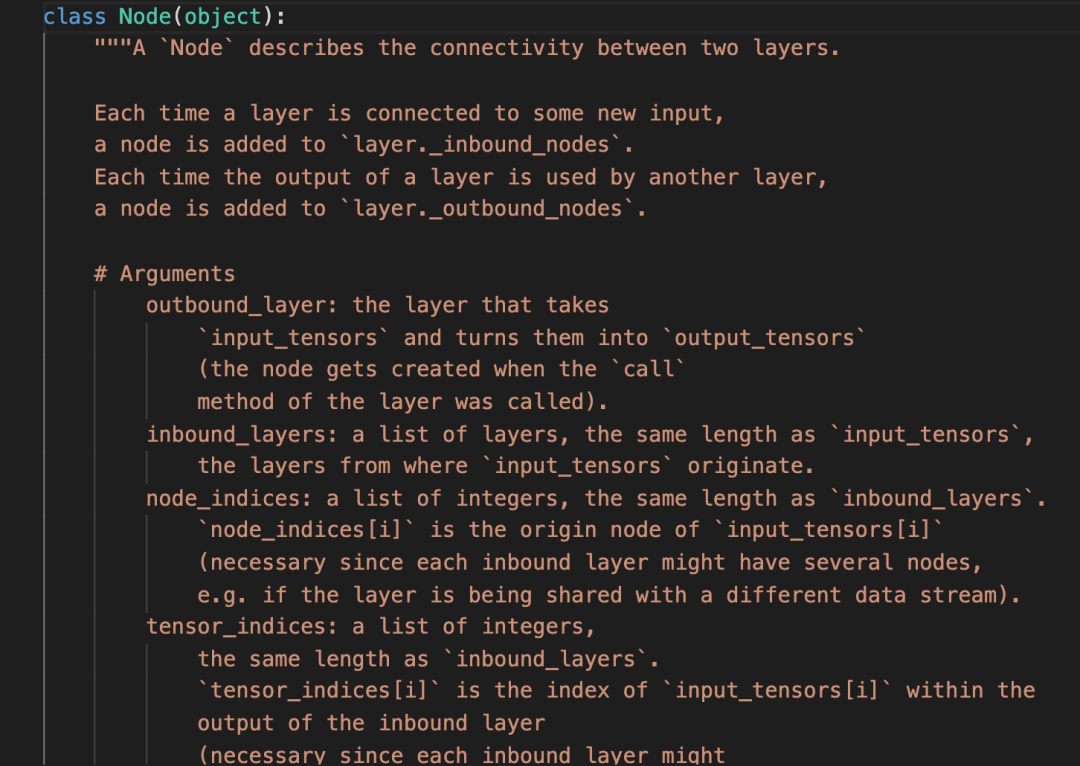
这里讲,Node描述了两个层之间的连接。
既然如此,Node的创建应该是在两个Layer建立连接的时候。两个Layer什么时候会建立连接呢?
对,就是调用layer的call方法的时候。那我先来看看在call方法中是不是有创建Node和添加Node的操作吧。
这个过程找起来略微复杂。首先,我找到了__call__方法。如下所示:
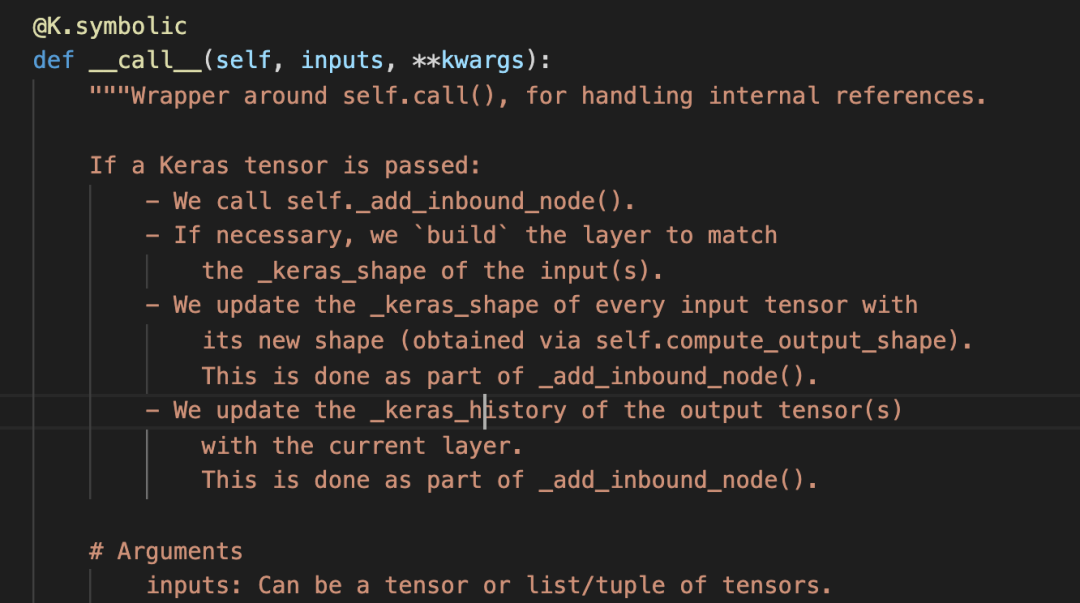
里面有这样的方法调用:
由于Node涉及到两层,所以这里的input output究竟是指的哪一层的,很容易引起混乱。
我是这样帮助记忆的。
self._add_inbound_node方法, 这个self指的是被call的layer,这个方法也正是要往该layer中添加节点。同理,这个方法的中的in相关的变量自然就是传给这个layer的,out相关的变量,自然就是这个layer输出的变量。
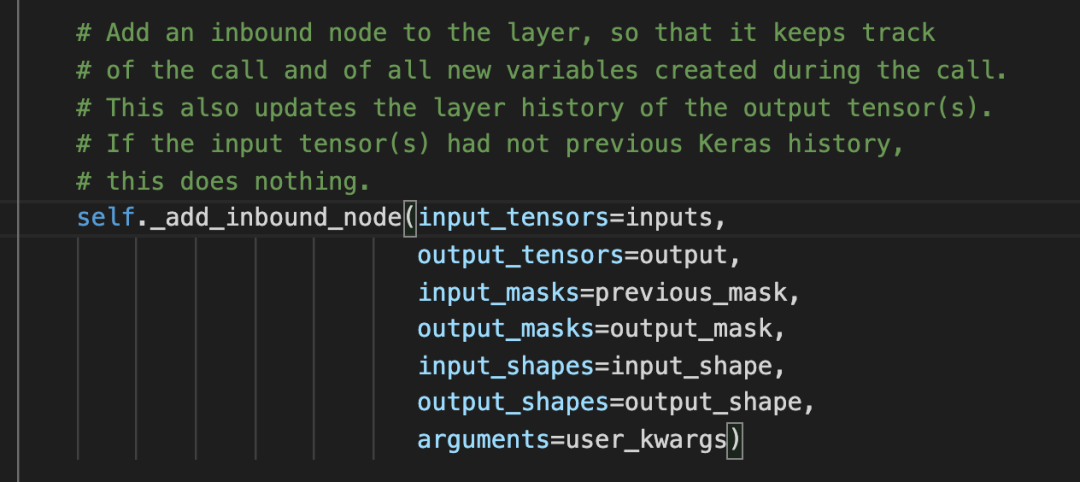
self._add_inbound_node方法中,终于找到了创建Node的方法:
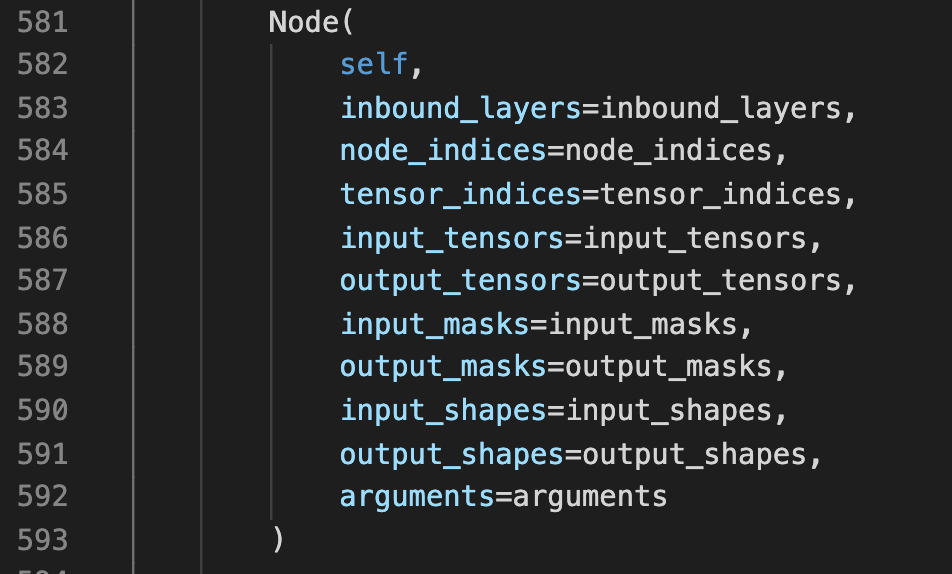
找到添加node的地方
但是并没有看到add_node之类的操作,这让我有点失望,不过看到Node创建的第一个参数是self,这就是我们要添加node的layer。我隐隐觉得,Node创建的时候,是不是就把自己给添加到layer中了。
于是,追踪到Node的创建方法,转了一圈,回到原地。
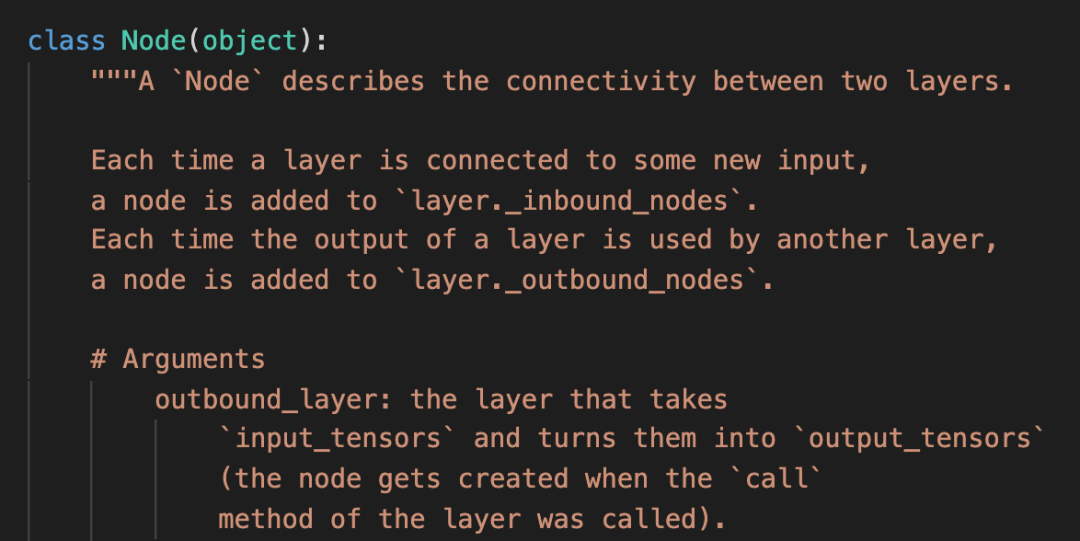
首先,我看到传进来的self layer 被命名成了outbound_layer。然后,果然在下面看到了添加node的操作。
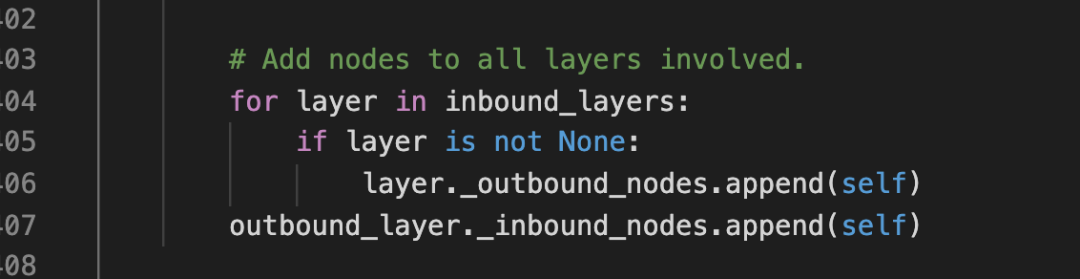
这个node被添加进了被call的layer的inbound_nodes。同时还被添加进了所有call这个layer的outbound_nodes中。
简单讲,就是layer调用,就会在inbound_nodes中添加一个节点,layer调用别人,就会在outbound_nodes中添加一个节点。
至此,我基本清楚了Node和Layer的区别。也更深刻理解了,node就是两个层之间的连接这句话的含义。
看了这么久,终于把前107行的内容完全理解了。中间来回已经跳转了很多地方,相信后面的阅读会快一点的。
今天开始看108-175行,没啥目标,遇到好奇的点,就深挖一下。
108-175
首先,对114行的注释比较感兴趣
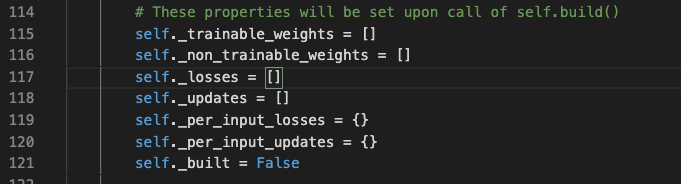
那我就来看看,这些量是如何在build方法中设置的吧。 这些变量可大致分成三类:
weights
loss
updates
最后的_built是一个是否build的标志位。
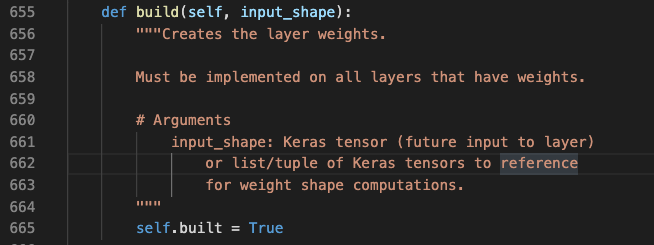 竟然是一个模板方法,留空了。只看到了built被置为True了。那就找一个最基本的layer来看看,当然是选Dense了。
竟然是一个模板方法,留空了。只看到了built被置为True了。那就找一个最基本的layer来看看,当然是选Dense了。
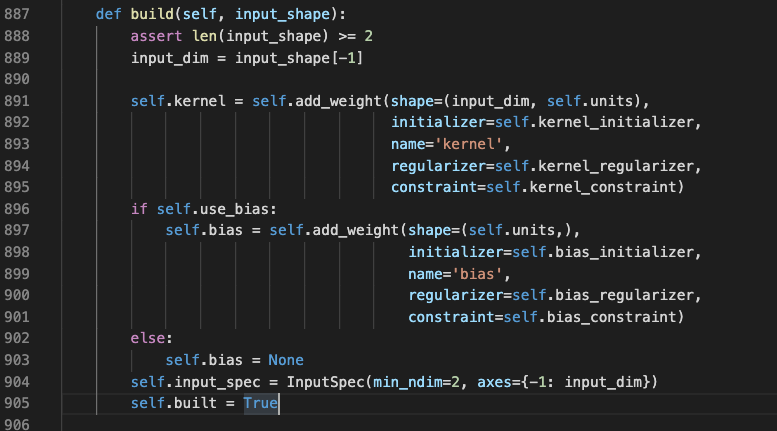 看到里面初始化了input_spec。没看到想看的内容,于是继续来到add_weight方法中。
看到里面初始化了input_spec。没看到想看的内容,于是继续来到add_weight方法中。
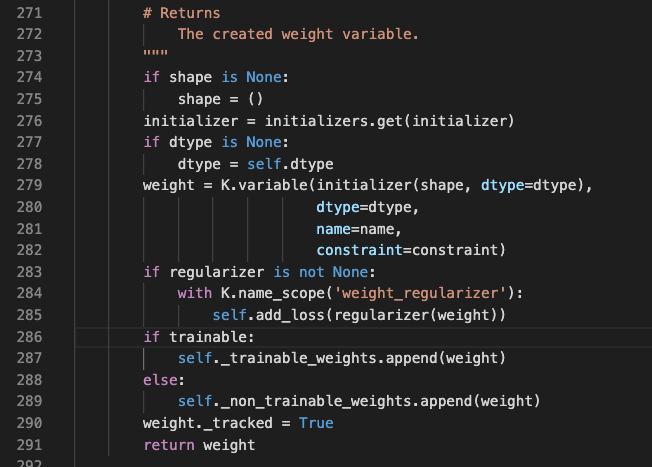
首先,这里可以清楚地看到_trainable_weights和_non_trainable_weights的添加。这就是决定weights是否可训练的地方。
对于loss的添加,还需要进一步跳到 add_loss方法中。
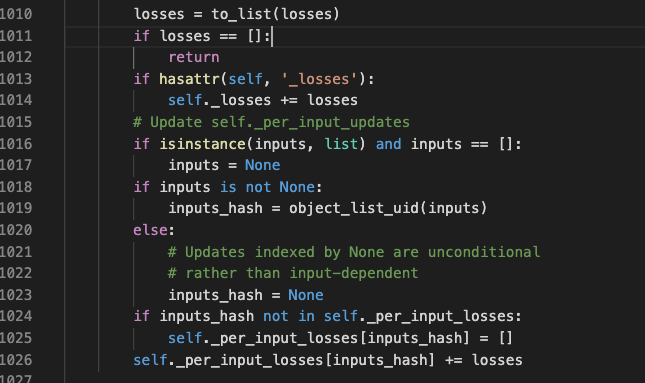
这里首先看到,传进来的losses被添加进了_losses这个属性中。
比较感兴趣的是它下面的几行代码。这里显示了,如果losses是依赖传入的inputs,为了记录这个信息,会将这些losses加入_per_input_losses中,key就是inputs的hash值。
正当我准备返回的时候,发现add_loss方法下面就是add_update,并且二者是实现非常相似。
此时,我想搞清楚,updates究竟有什么用?说是layer的更新op。找个例子看看吧。
这一找,发现了一个重要的keras的知识点。准备明天更新吧。专门写写updates。
上篇文章中,预告这次要盘一盘layer中的_updates,今天它来了。
108-175
首先,看到在118行,初始化了_updates。

然后,看到在Layer中有两个地方引用了它:

第一个引用是这样的:
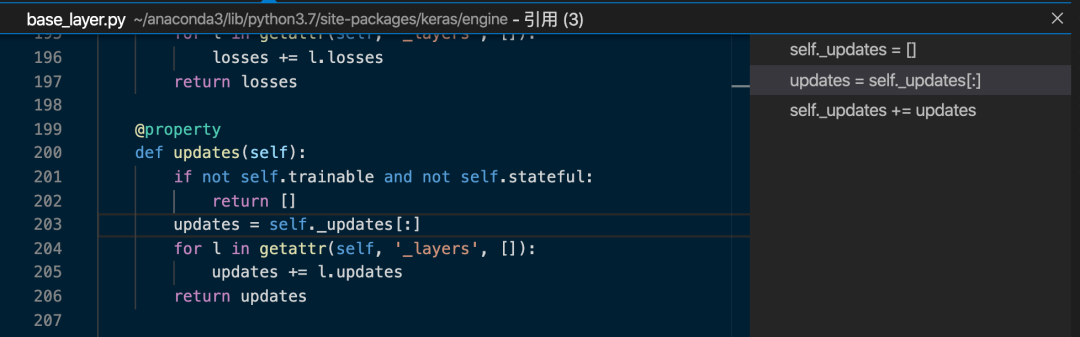
看到它开头的if判断,这是说,如果该Layer trainable是False,并且stateful也是False,就直接返回[]
说人话,要有_updates,该Layer至少要是trainble或者stateful的。
然后看到下面,通过一个循环,把该layer以及该layer包含的所有的layers的updates全加到一起后返回了。
第二个引用我们昨天已经涉及过了,就是add_update。
看完后,心中的疑问没有解开:
1、为什么需要updates
2、到底哪里使用了updates,如何使用的
是不是很像侦探判案,突然线索中断?
为了搞清楚上面的两个疑问,我查了一下,得出如下信息:一个Layer中,weights的更新,通常是反向梯度传导。这类weights放在self._trainable_weights。
但weights也可以是non_trainable,这类weights放在self._non_trainable_weights。
但是,这只是说明,此类weights不能通过反向梯度更新,并不是说它就一定不能更新了。
这类weights的更新,就可以使用_updates来进行。
最典型的,就是BatchNormalization。下面,我将截取BatchNormalization中的一些代码片段,来说明一下。这里不会具体细致地讲解BatchNormalization。
具体源码在keras.layers.normalization.BatchNormalization中。

看到,这里的moving_variance的trainable属性是False。但是它在这里通过add_update进行了更新。
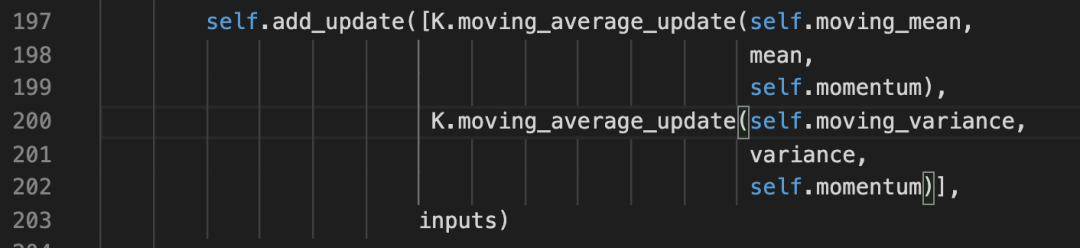
小小的疑问
还有一个小小的疑问,这个update具体的动作究竟在什么时候发生呢?上面的代码片段是在call方法中的。这里的add_update相当于update的登记操作。
我猜想,当通过反向梯度更新那些trainable的weights时,就会同时执行这些登记过的update。
为了验证这个猜想,我打开了Model的源码,在 _make_train_function中,发现了如下的代码:
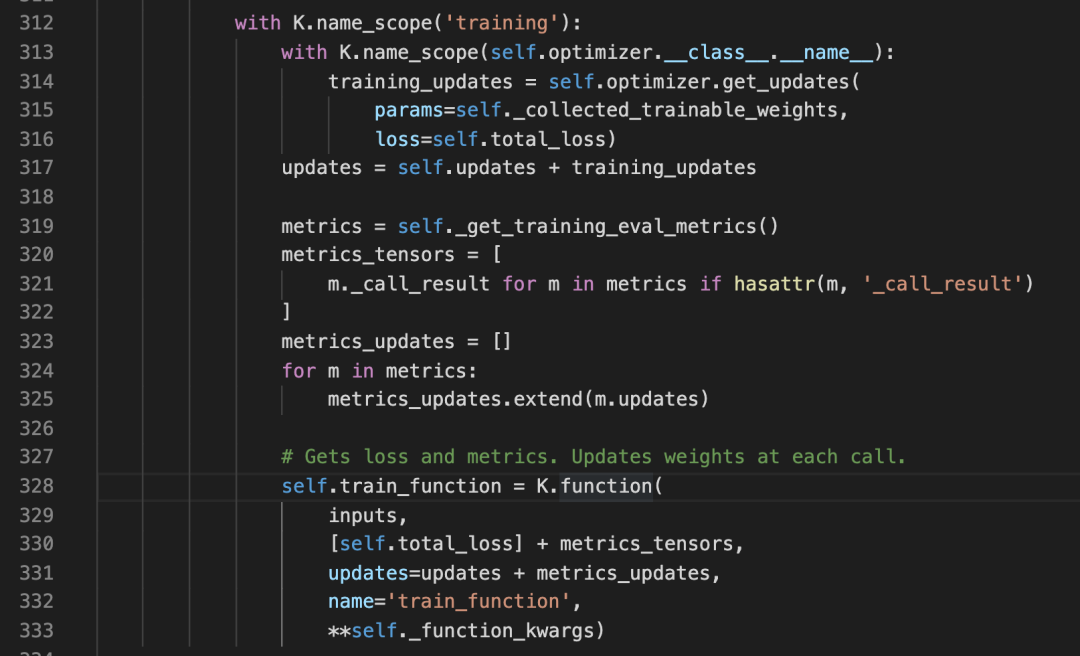
果然,这里把通过optimizer计算得来的training_updates和原有的_updates 做了合并,然后送入K.function中了。
然后我们继续来到K.function中

于是,我们进一步深入Function
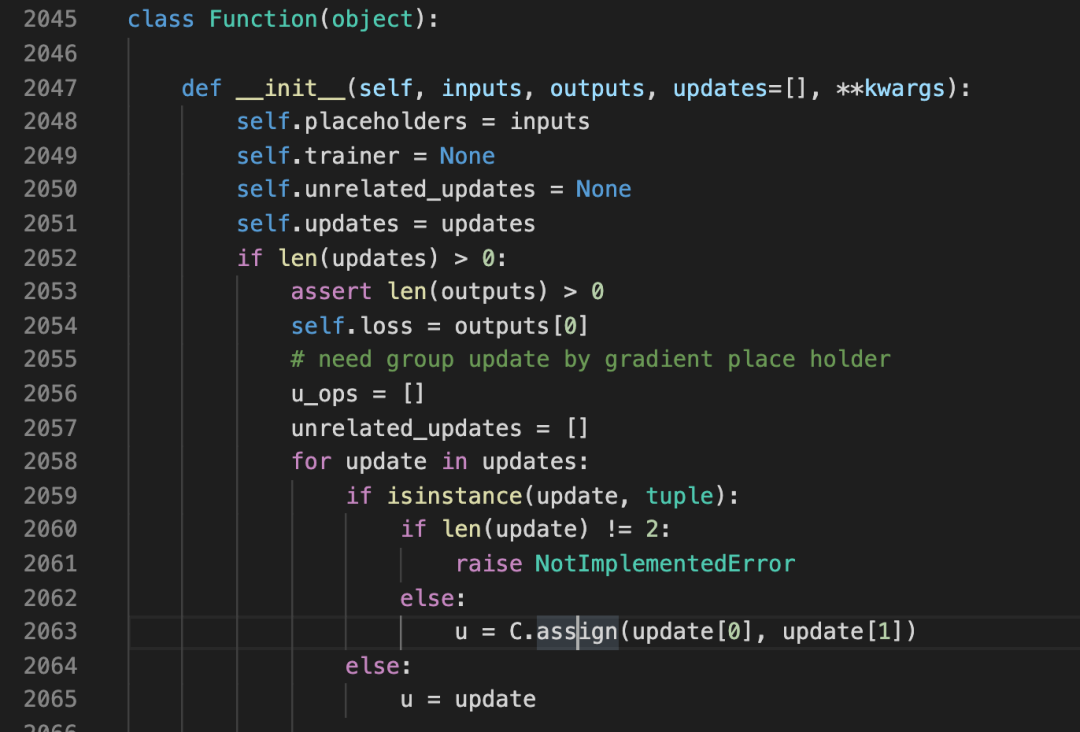
可以看到,在初始化中, u = C.assign(update[0], update[1])就是我们的更新操作,这些u被放入一个数组中了。然后就是对该数组的各种处理,抓大放小,直接查看一下Funtion的__call__方法。
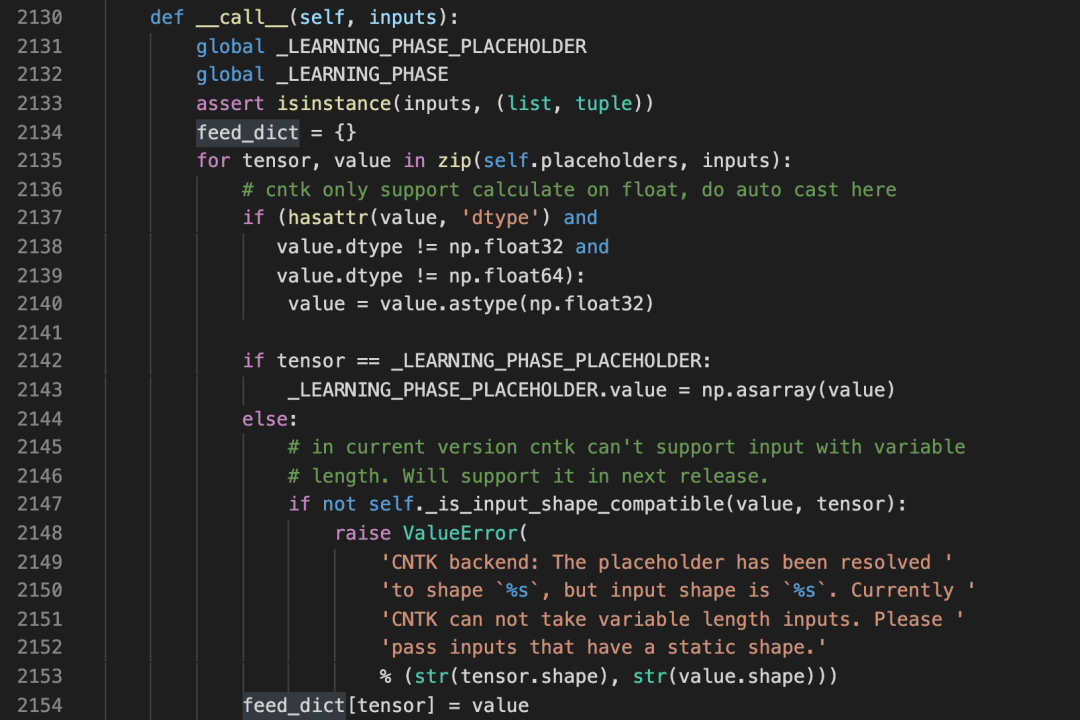
这里的代码读起来大致感觉到是执行了update操作。但是由于已经涉及到不同的backend,读起来就不太容易理解。上面截图的代码是cntk_backend。
不管怎么样,至此,算是基本搞清楚了这个updates是做什么的。
读完了第118行,下次继续。
上篇文章,只读了一行,就是118行。今天继续。保持冷静,不急不躁,切实要求自己,将每一行真正看懂后再继续。
108-175

读到这里,对_per_input之类的属性有了更系统的理解。简单说,就是某个变量如果是和某几个input有关,就用这几个input创建一个key,变量的值作为value。比如,loss,update都是这样的,这在前面的阅读代码中可以看到。
built变量之前也看过了,就是调用了build方法的标志。
_metrics这块儿,准备留一个专题来写。现在,简单将它看作类似losses之类的东西就行。
136行,allowed_kwargs,用来控制允许的keyword参数。这种方法在python库中很常见,一是可以用来检查用户错误的输入,二是可以用来进行版本控制。比如,在tensorflow中,经常看到警告,说某个参数在未来将会被弃用。就是用这种方法实现的检查和警告。

这里显示了layer的默认命名方法。进入K.get_uid方法中看看。
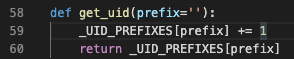
哦,就是将该layer名称为key的value直接加1。这一点,查看model的summary时,那些layer的名称,能看的更明白一些。layer名称后面的数字,就表示了这个layer被实例化了多少次。
154行,trainable这个参数,如果不设置,默认就会设置成True。
155-175
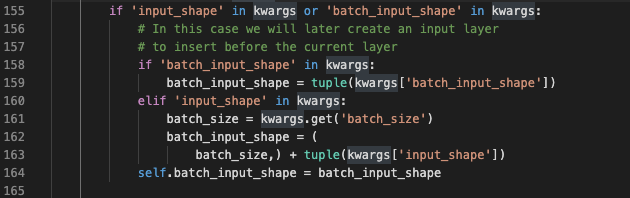 这里看到,keras 会使用input_shape 和batch_size来拼出batch_input_shape。
这里看到,keras 会使用input_shape 和batch_size来拼出batch_input_shape。
按这里的方法,提供input_shape时,必须同时提供batch_size。可是平时在是使用Input时,并没有提供batch_size。于是,我跳到了Input的初始化中,一探究竟。
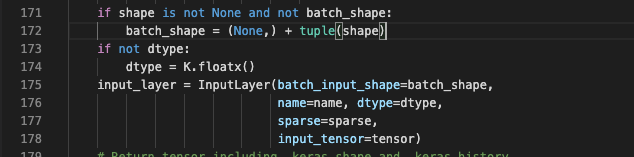 原来,这里直接用None拼接出了batch_input_shape。了然!
原来,这里直接用None拼接出了batch_input_shape。了然!
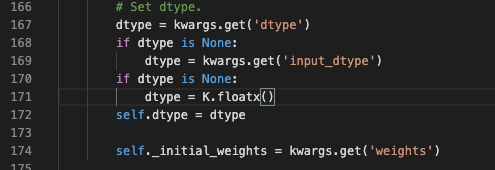
这里设置了数据类型,如果你没有设置,默认的是K.floatx()。
需要注意一下,这里有个_initial_weights,用来对weights进行初始化。
看一下它的使用时机。在__call__方法中。
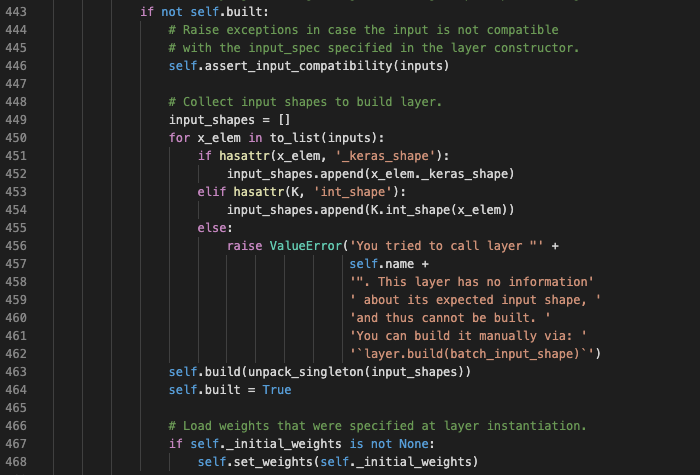
可以看到,如果layer还没有build,就会使用这个weights进行初始化。如果已经build了,就不会再次初始化。这是我一开始感到迷惑的地方。
这__call__方法的调用时机,用一个例子来说明一下:
Dense(2)(a)
这里,就调用了Dense的__call__方法。
至此,阅读完了Layer的初始化方法。
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01