gpt2 tokenizer源码解析
2023-01-10
上一篇文章中,分析了bert的tokenizer的细节,本篇继续分析gpt2的tokenizer的细节。 bpe的基本原理可以参考这篇文章:https://huggingface.co/course/chapter6/5?fw=pt 该tokenizer整体调用入口是encode方法。
"""Byte pair encoding utilities"""
import os
import json
import regex as re
from functools import lru_cache
@lru_cache()
def bytes_to_unicode():
"""
Returns list of utf-8 byte and a corresponding list of unicode strings.
The reversible bpe codes work on unicode strings.
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
This is a signficant percentage of your normal, say, 32K bpe vocab.
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
And avoids mapping to whitespace/control characters the bpe code barfs on.
将256个byte值映射到一个unicode字符上,绕开空白符和控制符。
"""
bs = list(range(ord("!"), ord("~")+1))+list(range(ord("¡"), ord("¬")+1))+list(range(ord("®"), ord("ÿ")+1))
cs = bs[:]
n = 0
for b in range(2**8):
if b not in bs:
bs.append(b)
cs.append(2**8+n)
n += 1
cs = [chr(n) for n in cs]
return dict(zip(bs, cs))
def get_pairs(word):
"""Return set of symbol pairs in a word.
Word is represented as tuple of symbols (symbols being variable-length strings).
两个字节作为一个pair,上面的函数已经将每个byte映射到一个字符了。
"""
pairs = set()
prev_char = word[0]
for char in word[1:]:
pairs.add((prev_char, char))
prev_char = char
return pairs
class Encoder:
def __init__(self, encoder, bpe_merges, errors='replace'):
self.encoder = encoder
self.decoder = {v:k for k,v in self.encoder.items()}
self.errors = errors # how to handle errors in decoding
self.byte_encoder = bytes_to_unicode()
self.byte_decoder = {v:k for k, v in self.byte_encoder.items()}
self.bpe_ranks = dict(zip(bpe_merges, range(len(bpe_merges))))
self.cache = {}
# Should haved added re.IGNORECASE so BPE merges can happen for capitalized versions of contractions
#这里是拆分token的正则,注意这里的re表示的是regex这个库
#\p{L}表示一个letter
#\p{N}表示一个number
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
def bpe(self, token):
if token in self.cache:
return self.cache[token]
word = tuple(token)
# 第一次调用时获得所有的双字节字符 假设word:abcd 那么 pairs: ab bc cd
pairs = get_pairs(word)
if not pairs:
return token
while True:
#取得频率最高的一个bigram
bigram = min(pairs, key = lambda pair: self.bpe_ranks.get(pair, float('inf')))
if bigram not in self.bpe_ranks:
break
first, second = bigram
new_word = []
i = 0
#这个循环就是找到所有的bigram,将他们合并到一起加入到new_word
while i < len(word):
try:
#找到first字符首次出现的位置j
j = word.index(first, i)
# 将j之前的字符加入到new_word中,注意是extend
new_word.extend(word[i:j])
i = j
except:
#没有找到的话,将剩余的字符加入到new_word中,new_word中是进行完此轮合并后的结果,用来进行下轮迭代的word
new_word.extend(word[i:])
break
#找到了bigram,将其合并成一个,加入new_word
if word[i] == first and i < len(word)-1 and word[i+1] == second:
new_word.append(first+second)
i += 2
else:#没有找到bigram,将word[i]加入,修改i,继续往下寻找bigram
new_word.append(word[i])
i += 1
new_word = tuple(new_word)
word = new_word
if len(word) == 1:
break
else:
#获得新的pairs,继续下一轮合并
pairs = get_pairs(word)
#将最终的token序列用空格连接
word = ' '.join(word)
self.cache[token] = word
return word
def encode(self, text):
bpe_tokens = []
for token in re.findall(self.pat, text):
#将token用utf8编码,然后逐个byte映射成相应的字符
token = ''.join(self.byte_encoder[b] for b in token.encode('utf-8'))
bpe_tokens.extend(self.encoder[bpe_token] for bpe_token in self.bpe(token).split(' '))
return bpe_tokens
def decode(self, tokens):
text = ''.join([self.decoder[token] for token in tokens])
text = bytearray([self.byte_decoder[c] for c in text]).decode('utf-8', errors=self.errors)
return text
def get_encoder(model_name, models_dir):
with open(os.path.join(models_dir, model_name, 'encoder.json'), 'r') as f:
encoder = json.load(f)
with open(os.path.join(models_dir, model_name, 'vocab.bpe'), 'r', encoding="utf-8") as f:
bpe_data = f.read()
bpe_merges = [tuple(merge_str.split()) for merge_str in bpe_data.split('\n')[1:-1]]
return Encoder(
encoder=encoder,
bpe_merges=bpe_merges,
)
byte相当于字符, encoder中是字符组成的词和编号, vocab.bpe表示的字符合并成词的优先级顺序。 vocab.bpe数据示例:
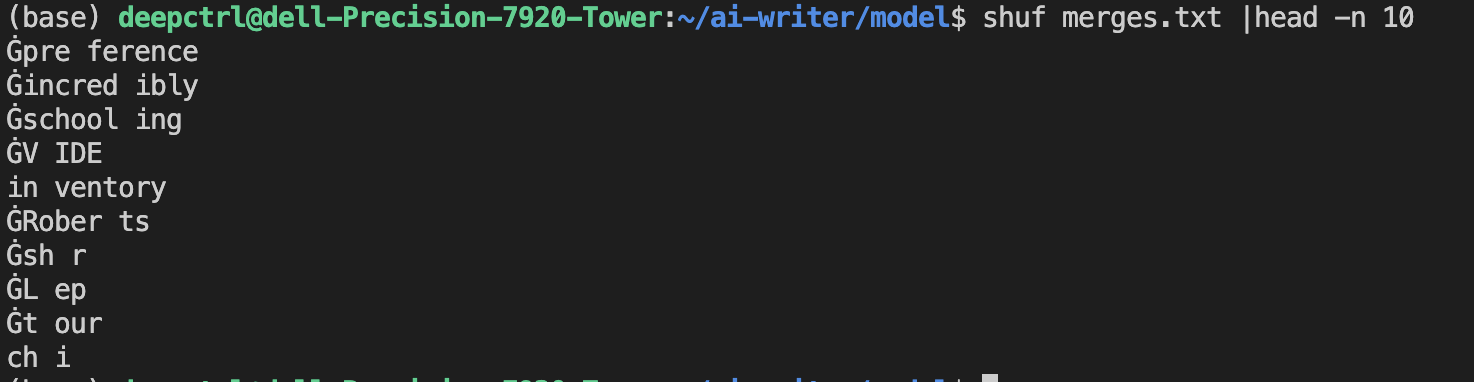
encoder.json数据示例:

原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01