CUDA矩阵转置要点
2022-02-26
在kernel执行过程中,执行了两个相互独立的索引映射。
1、第一个映射
第一个映射比较简单,就是根据线程索引映射到原始矩阵的全局内存地址。
分成两步完成,第一步是映射到矩阵的坐标。
ix = blockIdx.x \* blockDim.x + threadIdx.x
iy = blockIdx.y \* blockDim.y + threadIdx.y
如下图所示:
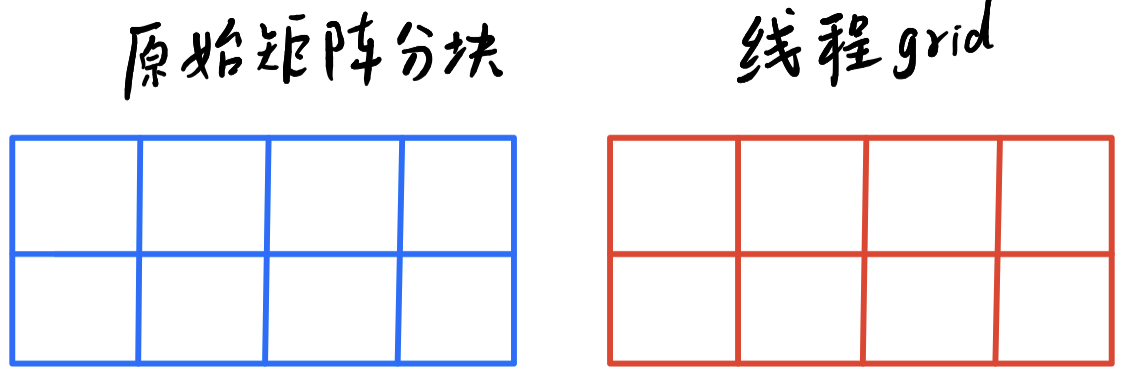
对应关系还是很直接的,符合我们的直观认识。
第二步是从矩阵坐标到内存地址的映射。
ti = iy * nx + ix
这里默认矩阵是行存储的。
找到矩阵元素地址后,就可以写入共享内存。
tile[threadIdx.y][threadIdx.x] = in[ti]
__syncthreads();
这里使用同步线程,是为了确保整个数据块都缓存到了共享内存中,防止下面要写的元素不在共享内存中的问题。
2、第二个映射
第二映射就不是很直观了,是线程索引到转置后的矩阵的坐标的映射。 如下图所示:
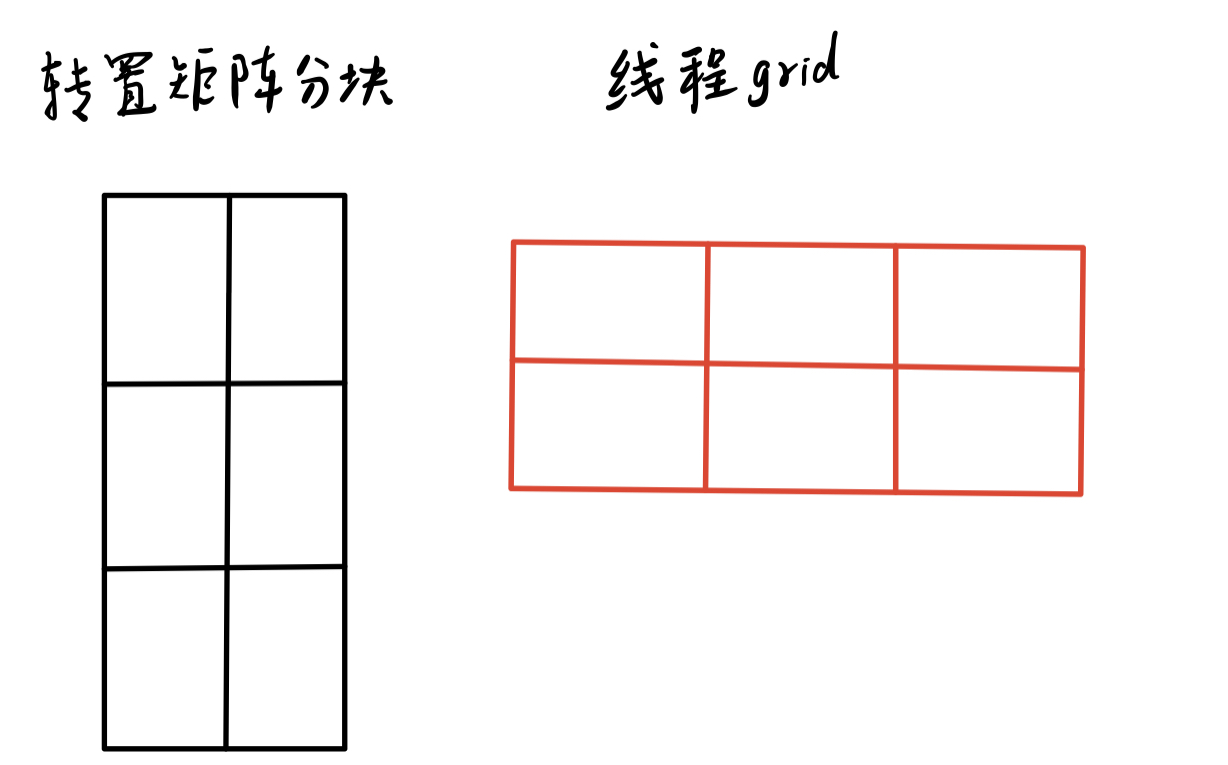
这里的映射,可以分成两步,第一步是块与块的映射。
我们很容易发现,只要将线程的block索引的x和y换一下,就可以完成。
ix = blockIdx.y * blockDim.y
iy = blockIdx.x * blockDim.x
第二步,是块内的映射,即如下图所示:
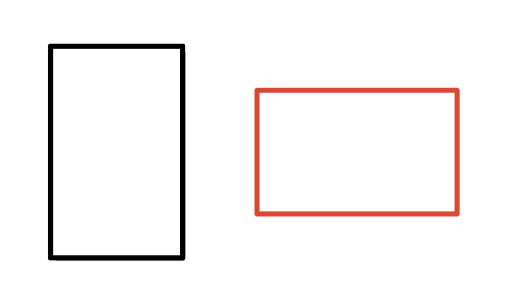
这里需要注意一点,就是虽然两个块的形状不一样,但是它们包含的元素个数还是一样的,不然就没办法完成映射了。
这里的映射略有技巧,如下代码所示:
bidx = threadIdx.y * blockDim.x + threadIdx.x
irow = bidx / blockDim.y
icol = bidx % blockDim.y
通过上面的映射关系,我们就完成了块内的映射。这种映射的实质是将线程块中的列映射到矩阵中的行。需要注意的是,这种映射,是我们人为构造出来的,目的是为了在写入时,可以实现连续的全局内存写入,提升内存的带宽利用率。因为从直观上,将x和y调换一下进行映射,更加简单直观。
将块的映射和块内映射结合到一起,我们就可以得出转置矩阵的坐标:
ix = blockIdx.y \* blockDim.y + icol
iy = blockIdx.x \* blockDim.x + irow
同样的,有了矩阵坐标,就可以求出全局内存的地址。
to = iy * ny + ix
还有一点需要注意,(irow, icol)是转置矩阵的块内坐标,但是我们共享内存中保存的是原始的矩阵块,所以在取数时,需要将行列再换成原始矩阵的块内坐标,即(icol, irow)。
3、 分析映射性能
我们只分析一点,就是写出的全局内存地址:
\[\begin{aligned} to &= iy * ny + ix \\ &=(blockIdx.x * blockDim.x +irow)*ny \\ &\quad + blockIdx.y * blockDim.y + icol \\ &= (blockIdx.x * blockDim.x + bidx / blockDim.y)*ny \\ &\quad + blockIdx.y * blockDim.y + bidx \% blockDim.y \\ &=(blockIdx.x * blockDim.x \\ &\quad +(threadIdx.y* blockDim.x + threadIdx.x) / blockDim.y)*ny \\ &\quad + blockIdx.y * blockDim.y \\ &\quad + (threadIdx.y* blockDim.x + threadIdx.x) \% blockDim.y \end{aligned}\]看等式最后面一项
\[(threadIdx.y* blockDim.x + threadIdx.x) \% blockDim.y\]这个值是随着threadIdx.x的递增而递增的,从而可以实现连续的全局内存写入。
至于共享内存的读取,其实也可以通过填充来避免bank冲突,但这不是这里的重点。
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01