CUDA中矩阵相乘的stride技巧
2022-03-12
1、没有stride技巧时的情况
使用cuda计算矩阵相乘时,核心的思路是构建一个二维的grid和一个二维的block,使用适当的映射方法,将block映射到结果矩阵中相应的块。然后编写kernel。如下图所示:
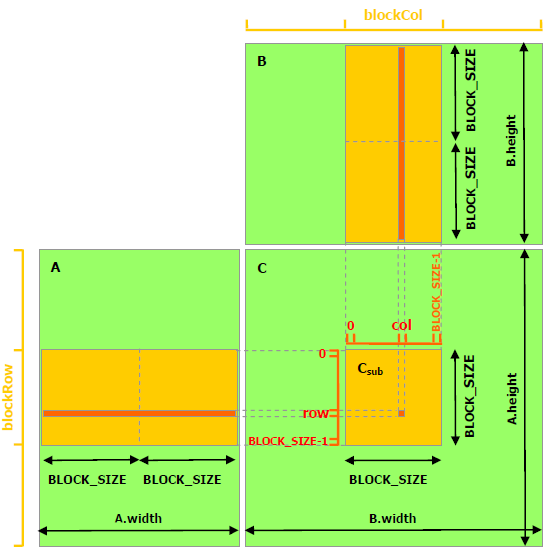
上图的映射,可以认为一个线程的block恰好映射一个同样大小的结果矩阵C中的块。 就上面这个图而言,可以看出来,需要一个grid为3X3,block是BLOCK_SIZE X BLOCK_SIZE的配置。
2、使用stride技巧时的映射情况
使用stride,就是改变了线程的block和结果矩阵C中相应大小的块映射关系,不再是一对一,而是一对多。可以从下图中看到:
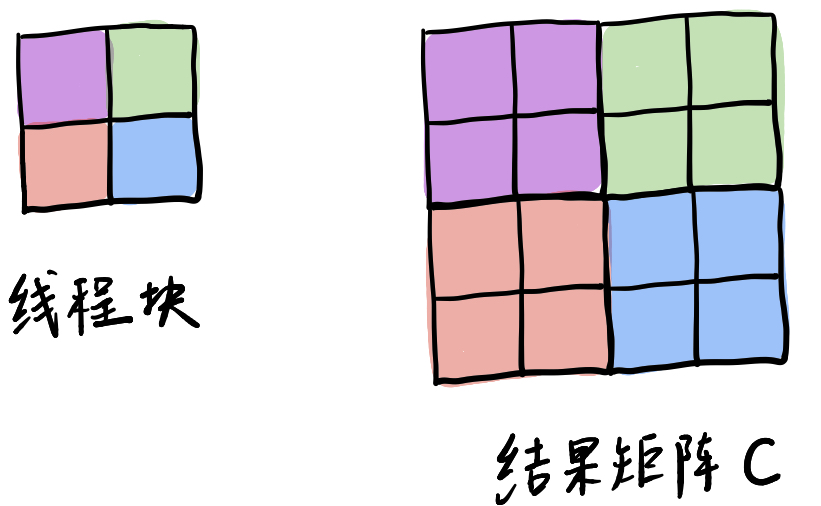
原先一对一的关系现在变成了一对四,stride是2,这样,就减少了线程块的个数。
对于每个线程来说,它所负责计算的C元素的数量也从原来的1个,变成了stride X stride个。
使用这种优化方法,可以提高计算访存比,但较少的block,也可能带来活跃warp减少,所以stride的最佳值,需要通过具体实验获得。
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01