对比学习训练技巧
2022-03-19
总结一下自己在一个文档检索项目中使用对比学习时的炼丹经验.
- 更大的batch size
- 更难的负样本,从同一个类型的句集中挑选负样本
- 使用余弦相似度,更适合K-means
- 相似度倍增,实际经验C=20较好
- 随机的负样本仍然是必需的,因为要优化global structure,我的经验60%较好,这取决于数据集
- 使用(a,p,n)三元组,a是anchor,p代表正例,n代表负例,要求与p尽可能相似
-
寻找好的负例技巧很关键,查找各种资料,典型的有根据数据集结构来寻找,比如问答数据集中,将低赞答案作为负例;其次,可以使用BM25寻找与p近似的文本,然后随机选择一个作为负例,这也是项目中实际使用的,效果很好。
- 持续训练,模型上线后,根据模型预测出的hard negative样本,继续训练,这是提升效果的大杀器。
- 负样本去噪。因为训练时正样本指定了一个,实际上可能有多个,其他正样本会被误作为负样本,根据模型预测结果识别出这部分数据,效果提升肉眼可见。
- 负样本去噪技巧。同时训练bi-encoder和cross-encoder两个模型,然后将bi-encoder中相近的点使用cross-encoder进行预测,低于一定阈值的作为负样本。
-
解决cross-encoder中的阈值确定难题,使用MarginMSELoss继续训练bi-encoder。流程如下:
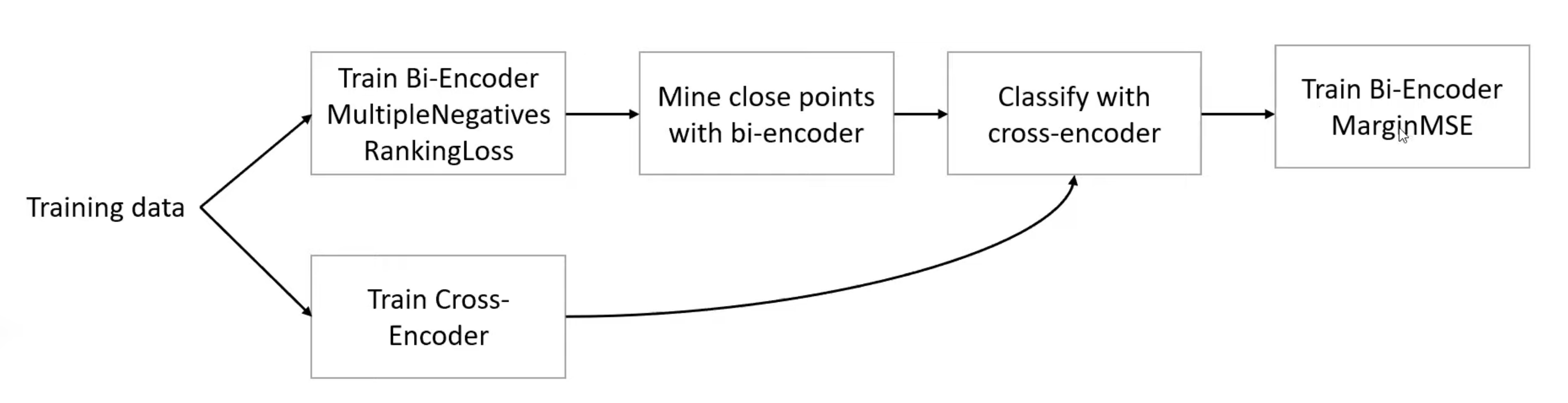 具体效果,在我们的数据上有提升,但是没有吹的那么玄乎。这实际上是一种知识蒸馏技术。
具体效果,在我们的数据上有提升,但是没有吹的那么玄乎。这实际上是一种知识蒸馏技术。 - 更大的数据,远胜过复杂的模型方法。上面的cross-encoder挑选负样本过于复杂,实际上,当我们又爬取了一些数据后,仅在简单的bi-encoder上训练,效果就轻松超过了复杂的训练方法。
Refs: https://www.youtube.com/watch?v=XHY-3FzaLGc
原创文章,转载请注明出处,否则拒绝转载!
本文链接:抬头看浏览器地址栏
上篇:
SimCSE核心源码解读
最新文章
- 2025年文章总结 2025-12-29
- Flux-Text执行流程记录 2025-07-14
- livetalking数字人执行流程 2025-07-13
- Step1X-Edit执行流程(二) 2025-06-25
- Step1X-Edit执行流程(一) 2025-06-24
- 女儿突然知道关心人了 2025-04-28
- shfl_xor_sync原语 2025-04-22
- MHA, GQA, MQA, MLA的代码 2025-04-01
- Bank Conflicts简介 2025-03-05
- FlashAttention解读 2025-03-01